Project : House Prices: Advanced Regression Techniques¶
1. Data Introduce¶
1.1 Purpose : Predict SalePrice¶
1.2 Data set:¶
Use house data in Ames. Iowa
Train Data : It consists of 81 variables and 1460 house data
Test Data : It consists of 80 variables and 1459 house data
Total Data : 2919 house data
- Source : House Prices: Advanced Regression Techniques
1.3 Evaluation¶
- Root-Mean-Squared-Error (RMSE)
$$ RMSE = \sqrt{\frac{1}{n}\Sigma_{i=1}^{n}{\Big(\frac{d_i -f_i}{\sigma_i}\Big)^2}} $$
2. Exploring the Data¶
Let's start with importing the necessary libaries, reading in the data and checking out the dataset.
Note that the last column from this dataset, 'SalePrice' will be our target label. All other columns are features about each individual in house database
# Import libraries necessary for this project
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.stats.api as sms
from scipy.stats import norm, skew
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Import visualisation libraries
import matplotlib.pyplot as plt
import seaborn as sns
# Pretty display for notebooks
%matplotlib inline
# Allows the use of display() for DataFrames
from IPython.display import display
# Ignore the warnings
import warnings
warnings.filterwarnings('ignore')
# Load the dataset
train = pd.read_csv("./Input/train.csv")
test = pd.read_csv("./Input/test.csv")
# Success - Display the first record
display(train.head(n=1))
(1) Check data¶
print("Train data : ", train.shape)
print("Test data : ", test.shape)
Comments :¶
There are 1460 instances of training data and 1460 of test data. Total number of attributes equals 81
(2) Status of Train data¶
train.describe()
Comment :¶
- Count :Some data such as LotFrontage and MasVnrArea are lost
- Mean & 50% : Some data is biased to a certain value
(3) Explore SalePrice¶
plt.figure(figsize=(17,6))
plt.subplot(131)
sns.distplot(train["SalePrice"])
plt.subplot(132)
stats.probplot(train["SalePrice"], plot=plt)
plt.subplot(133)
sns.boxplot(train["SalePrice"])
plt.tight_layout()
plt.show()
print(train["SalePrice"].describe(),"\n")
print("Skewness: %f" % train['SalePrice'].skew())
print("Kurtosis: %f" % train['SalePrice'].kurt())

Comments :¶
- It is apparent that SalePrice doesn't follow normal distribution and has positive skewness.
(4) SalePrice log transformation¶
nomalized_SalePrice = np.log1p(train["SalePrice"])
plt.figure(figsize=(17,6))
plt.subplot(131)
sns.distplot(nomalized_SalePrice)
plt.subplot(132)
stats.probplot(nomalized_SalePrice, plot=plt)
plt.subplot(133)
sns.boxplot(nomalized_SalePrice)
plt.tight_layout()
plt.show()

Comment:¶
- After log transformation, it seems to follow normal distribution.
2-2 Feature Type¶
(1) Check Numerical and Catergorical variables¶
# Because the MSSubClass variable is a category value, change numeric data to character data
train["MSSubClass"] = train["MSSubClass"].astype('str')
# Divide into numeric and categorical variables
numerical_features = []
categorical_features = []
for f in train.columns:
if train.dtypes[f] != 'object':
numerical_features.append(f)
else:
categorical_features.append(f)
print("Numerical Features Qty :", len(numerical_features),"\n")
print("Numerical Features : ", numerical_features, "\n\n")
print("Categorical Features Qty :", len(categorical_features),"\n")
print("Categorical Features :", categorical_features)
(2) Graph for numerical features with SalePrice¶
It also would be useful to see how sale price compares to each independent variable.
fig, ax = plt.subplots(6,6, figsize = (20,20))
for idx, n in enumerate(numerical_features):
if n == 'SalePrice':
continue
sns.regplot(x=n, y='SalePrice', data=train, ax = ax[idx//6,idx%6])
ax[idx//6, idx % 6].set(yticklabels=[])
ax[idx//6, idx % 6].set(xticklabels=[])
continue

(3) Graph for categorical features¶
fig, ax = plt.subplots(8,6, figsize = (20,20))
for idx, n in enumerate(categorical_features):
sns.countplot(x=n, data=train, ax = ax[idx//6, idx % 6])
ax[idx//6, idx % 6].set(yticklabels=[])
continue

2-3 Relationship between SalePrice and variables¶
2-3-1 Area¶
# Make df_train set to check 2ndFloor and Basement
df_train = train.copy()
df_train["2ndFloor"] = "2ndFloor"
df_train["2ndFloor"].loc[df_train["2ndFlrSF"]==0] = "No 2ndFloor"
df_train["Basement"] = "Basement"
df_train["Basement"].loc[df_train["TotalBsmtSF"]==0] = "No Basement"
# Joint plot GrLivArea/saleprice
grid = sns.jointplot(x = "GrLivArea", y = "SalePrice", data=train, kind="reg")
grid.fig.set_size_inches(15,5)
# Strip plot GrLivArea/2ndFloor/saleprice
plt.figure(figsize = (20,8))
plt.subplot(211)
g = sns.stripplot(x = "GrLivArea", y = 'SalePrice', hue = "2ndFloor", data = df_train, alpha = 0.7)
g.set_xlabel('GrLivArea')
g.set_ylabel('SalePrice')
g.set_xticks([])
g.set_title('GrLiv & 2ndFloor - SalePrice')
# Strip plot GrLivArea/Basement/saleprice
plt.subplot(212)
b = sns.stripplot( x = "GrLivArea", y = 'SalePrice', hue = "Basement", data = df_train, alpha = 0.7)
b.set_xlabel('GrLivArea')
b.set_ylabel('SalePrice')
b.set_title('GrLivArea & Basement - SalePrice')
b.set_xticks([])
plt.show()


Comments :¶
1.GrLivArea is a linear relationship to house values and is heterogeneous.
2.If the house price is above $ 200,000, there are more houses on the second floor and a few houses without basement
2-3-2 Overall¶
# Graph for GrLivArea & OverallQual - SalePrice
plt.figure(figsize=(15,8))
ax1 = plt.subplot2grid((2,2), (0,0), colspan = 2)
for qual in range(1,11):
index = train.OverallQual == qual
ax1.scatter(train.GrLivArea.loc[index], train.SalePrice.loc[index], data=train, label= qual, alpha =0.5)
ax1.legend(loc = 0)
ax1.set_title("GrLivArea & OverallQual - SalePrice")
ax1.set_xlabel('GrLivArea & OverallQual')
ax1.set_ylabel('SalePrice')
# Graph for OverallQual - SalePrice
ax2 = plt.subplot2grid((2,2), (1,0))
sns.boxplot(x = "OverallQual", y = "SalePrice", data=train, ax= ax2)
ax2.set_title('OverallQual - SalePrice')
# Graph for OverallCond - SalePrice
ax3 = plt.subplot2grid((2,2), (1,1))
sns.boxplot(x = "OverallCond", y = "SalePrice", data=train, ax= ax3)
ax3.set_title('OverallCond - SalePrice')

Comments :¶
- 'OverallQual' seem to be related with 'SalePrice' and the box plot shows how sales prices increase with the overall quality. however, the 'OverallCond' seem to be not related.
2-3-3 Garage¶
# Graph for GarageArea & GarageCars - SalePrice
plt.figure(figsize=(15,6))
ax1 = plt.subplot(1,2,1)
for car in range(0,5):
index = train.GarageCars == car
ax1.scatter(x = train.GarageArea.loc[index], y = train.SalePrice.loc[index], data=train, label=car, alpha='0.5')
# Graph for GarageArea
ax1.legend()
ax1.set_title('GarageArea - SalePrice')
ax1.set_xlabel('GarageArea')
ax1.set_ylabel('SalePrice')
# Graph for GarageCars
ax2 = plt.subplot(1,2,2)
sns.stripplot(x = "GarageCars", y = "SalePrice", data=train,ax=ax2, jitter=True)
ax2.set_title('GarageCars - SalePrice')
ax2.legend()
plt.show()

Comments:¶
- The wider the GarageArea and the larger the number of cars (GarageCars), it can be seen that the higher the house price
2-3-4 Neighborhood¶
# Neighborhood variables are grouped by neighbors and then aggregated by average
Neighbor = train.pivot_table(index="Neighborhood",values="SalePrice", aggfunc='mean').sort_values(by = ["SalePrice"], ascending = False)
Neighbor = Neighbor.reset_index()
# The bar graph displays the aggregated data in the order of the highest to lowest price
g = sns.factorplot(x = "Neighborhood", y="SalePrice", data=Neighbor, size =8, kind="bar")
g.set_xticklabels(rotation=45)
g.fig.set_size_inches(15,5)
plt.show()

# High_price_neighbor is the house value of more than 250,000, Middle_price_neighbor is the neighbor of 250,000 ~ 150,000, and Low_price_neighbor is the remaining neighbor
def neighbor_level(x):
High_price_neighbor = ['NoRidge','NridgHt','StoneBr']
Middle_price_neighbor = ['Timber','Somerst','Veenker','ClearCr','Crawfor','NWAmes', 'Gilbert','Blmngtn', 'SWISU','Mitchel','CollgCr']
Low_price_neighbor = ['IDOTRR','Blueste', 'Sawyer','NAmes', 'BrDale', 'OldTown','MeadowV', 'NPkVill','BrkSide','Edwards']
if str(x) in High_price_neighbor:
return "high"
elif str(x) in Middle_price_neighbor:
return "middle"
elif str(x) in Low_price_neighbor:
return "low"
df_train["neighbor_level"] = df_train["Neighborhood"].apply(neighbor_level)
fig, ax = plt.subplots(5,8, figsize = (20,20))
for idx, n in enumerate(numerical_features):
sns.barplot(x="neighbor_level", y= n, data=df_train, ax = ax[idx//8,idx%8], order=['high', 'middle', 'low'])
ax[idx//8, idx % 8].set(yticklabels=[])
ax[idx//8, idx % 8].set_xlabel("")
ax[idx//8, idx % 8].set_ylabel(n)
continue

Comments:¶
- High group's Overall quality (overall quality), GrLivArea (living room size), and GargeArea (garage width) are high on the average, which is an important factor in predicting house prices
2-3-5 Year¶
# Correlation between YearBuilt and SalePrice
# Boxplot YearBuilt / SalePrice
plt.figure(figsize=(15,6))
fig = sns.boxplot(x="YearBuilt", y="SalePrice", data=train)
fig.axis(ymin=0, ymax=800000)
plt.xticks(rotation=90)
plt.show()
# Stripplot YearRemodAdd / YearBuilt
plt.figure(figsize=(15,6))
ax2 = plt.subplot(1,2,1)
sns.stripplot(x = train['YearBuilt'], y = train['YearRemodAdd'], alpha = 0.5,ax=ax2)
ax2.set_xticks([])
plt.xlabel('YearBuilt')
plt.ylabel('YearRemodAdd')
# Countplot YrSold
ax3 = plt.subplot(1,2,2)
sns.countplot(x = train['YrSold'], alpha = 0.5, ax=ax3)
plt.show()
# Stripplot YearBuilt / OverallQual
plt.figure(figsize=(15,6))
ax4 = plt.subplot2grid((2,2), (0,0), colspan = 2)
sns.stripplot(x = train['YearBuilt'], y = train['OverallQual'], alpha = 0.5,ax=ax4)
ax4.set_xticks([])
plt.xlabel('YearBuilt')
plt.ylabel('OverallQual')
# Countplot MoSold
ax5 = plt.subplot2grid((2,2), (1,0), colspan = 2)
sns.countplot(x = "MoSold", data=train, ax = ax5)
plt.show()



Comments :¶
- The price of recently built house is high.
- Houses that have not been remodeled are recorded in the same year as the year they were built.
- Remodeling took place after 1950 and most of the old houses were remodeled in 1950.
- The year of the sale is from 2006 to 2010, with the largest sale in 2009.
- The most active trading takes place in May, June, and July.
2-3-6 Fireplaces¶
# Stripplot Fireplaces / SalePrice
plt.figure(figsize=(15,10))
ax1 = plt.subplot2grid((2,2), (0,0), colspan = 2)
sns.stripplot(x = train['Fireplaces'], y = train['SalePrice'], alpha = 0.5, jitter = True, ax=ax1)
# Countplot FireplaceQu
ax2 = plt.subplot2grid((2,2), (1,0))
sns.countplot(x = "FireplaceQu", data=train, ax = ax2, order = ['Ex', 'Gd', 'TA', 'Fa', 'Po'])
# Boxplot FireplaceQu / OverallQual
ax3 = plt.subplot2grid((2,2), (1,1))
sns.boxplot(x = 'FireplaceQu', y = 'OverallQual', data = train, order = ['Ex', 'Gd', 'TA', 'Fa', 'Po'], ax=ax3)
plt.show()
# Stripplot FireplaceQu / Fireplaces / SalePrice
plt.figure(figsize=(15,10))
ax4 = plt.subplot(2,1,1)
sns.stripplot(x='FireplaceQu', y='SalePrice', hue='Fireplaces', data=train, jitter=True, alpha=0.6,order = ['Ex', 'Gd', 'TA', 'Fa', 'Po'], ax=ax4)
plt.show()


Comments:¶
- There is a price difference between a house with zero FirePlaces and a house with one FirePlaces.
- FireplaceQu and OverallQual are closely related.
- The lower the FireplaceQu, the lower the SalePrice
2-3-7 Basement Bath¶
# Stripplot BsmtQual / SalePrice
plt.figure(figsize=(15,6))
sns.stripplot(x = "BsmtQual", y = "SalePrice", data=train, jitter=True,\
order = ['Ex', 'Gd', 'TA', 'Fa'])
plt.figure(figsize=(15,6))
# Scatterplot BsmtFullBath
ax1 = plt.subplot(1,2,1)
for BSMT in range(0,5):
index = train.BsmtFullBath == BSMT
ax1.scatter(x = train.BsmtFullBath.loc[index], y = train.SalePrice.loc[index], data=train, label=BSMT, alpha='0.5')
# ax1.legend()
ax1.set_title('BsmtFullBath - SalePrice')
ax1.set_xlabel('BsmtFullBath')
ax1.set_ylabel('SalePrice')
# Stripplot BsmtHalfBath / SalePrice
ax2 = plt.subplot(1,2,2)
sns.stripplot(x = "BsmtHalfBath", y = "SalePrice", data=train,ax=ax2, jitter=True)
ax2.set_title('BsmtHalfBath - SalePrice')
plt.show()


Comment :¶
- The higher the quality of the bathroom, the higher the house price.
- In the case of HalfBath, the more the house price goes down
2-3-8 Room¶
# Stripplot TotRmsAbvGrd / SalePrice
plt.figure(figsize=(15,8))
ax1 = plt.subplot(2,1,1)
sns.stripplot(x='TotRmsAbvGrd', y='SalePrice', hue='TotRmsAbvGrd', data=train, jitter=True, alpha=0.6, ax=ax1)
# Countplot TotRmsAbvGrd
ax2 = plt.subplot2grid((2,2), (1,0))
sns.countplot(x = "TotRmsAbvGrd", data=train , ax = ax2, order = train["TotRmsAbvGrd"].value_counts().index)
# Boxplot TotRmsAbvGrd / OverallQual
ax3 = plt.subplot2grid((2,2), (1,1))
sns.boxplot(x = 'TotRmsAbvGrd', y = 'OverallQual', data = train, ax=ax3)
plt.show()
# Jointplot TotRmsAbvGrd / SalePrice
grid = sns.jointplot(x = "TotRmsAbvGrd", y = "SalePrice", data=train, kind="reg", size = 8)
grid.fig.set_size_inches(15,5)


Comment :¶
- The higher the number of rooms (TotRmsAbvGrd), the higher the house prices tend to be.
- The better the room, the better the quality of the house.
3. Feature Engineering¶
3-1 Missing Values¶
3-1-1 Join Train and Test set¶
Combine Train and Test data and process missing data at once
# Save lenth of train and test set
ntrain = train.shape[0]
ntest = test.shape[0]
# Combine Train and Test data
all_data = pd.concat((train, test)).reset_index(drop=True)
print("All data size is {}".format(all_data.shape))
3-1-2 Status of missing values¶
# To maintain the independence of all_data, copy it to all_data_cp and proceed with it
all_data_cp = all_data.copy()
# Drop saleprice column
all_data_cp.drop(['SalePrice'], axis=1, inplace=True)
# Chck missing values
all_data_null = all_data_cp.isnull().sum()
all_data_null = all_data_null.drop(all_data_null[all_data_null == 0].index).sort_values(ascending=False)
all_data_missing = pd.DataFrame({'Missing Numbers' :all_data_null})
all_data_null = all_data_null / len(all_data_cp)*100
# Barplot missing values
f, ax = plt.subplots(figsize=(15, 12))
plt.xticks(rotation='90')
sns.barplot(x=all_data_null.index, y=all_data_null)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
print("Variables with Missing Qty : " , all_data_missing.count().values)
print("Total Missing values Qty : " , all_data_missing.sum().values)

34 attributes have missing values. Most of times NA means lack of subject described by attribute, like missing pool, fence, no garage and basement.
3-1-3 Missing Values processing¶
MSSubClass
- Description : Identifies the type of dwelling involved in the sale
- Process : Missing values are filled with None because the data is evenly distributed and hard to judge by specific value
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")
SaleType
- Description: Type of sale
- Process : 87% of data uses WD (Warranty Deed - Conventional) method, so Missing Data is filled with WD
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
KitchenQual:
- Description : Kitchen quality
- Process : 52% of the total data is classified as TA (Typical / Average), so Missing Data is filled with TA
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
BsmtFinSF1 & BsmtFinSF2
- Description : Finished basement square feet
- Process : In both data, about 35% of the data is zero. Therefore, Missing Data is also filled with 0.
all_data['BsmtFinSF1'] = all_data['BsmtFinSF1'].fillna(0)
all_data['BsmtFinSF2'] = all_data['BsmtFinSF2'].fillna(0)
GarageCars & GarageArea & GarageYrBlt
- Description : Qty, Size, year of garage
- Process : Missing data means that there is no garage, so filling Missing Data with 0
all_data['GarageCars'] = all_data['GarageCars'].fillna(0)
all_data['GarageArea'] = all_data['GarageArea'].fillna(0)
all_data['GarageYrBlt'] = all_data['GarageYrBlt'].fillna(0)
TotalBsmtSF
- Description : Total square feet of basement area
- Process : Missing data means that there is no basement, so filling Missing Data with 0
all_data['TotalBsmtSF'] = all_data['TotalBsmtSF'].fillna(0)
BsmtUnfSF
- Description : Unfinished square feet of basement area
- Process : Missing data means that there is no basement, so filling Missing Data with 0
all_data['BsmtUnfSF'] = all_data['BsmtUnfSF'].fillna(0)
BsmtQual & BsmtCond
- Description : Evaluates the height and condition of the basement
- Process : Missing values in BsmtQual and BsmtCond data are converted to None because there is no basement
all_data['BsmtQual']=all_data['BsmtQual'].fillna('None')
all_data['BsmtCond']=all_data['BsmtCond'].fillna('None')
BsmtExposure & BsmtFinType1 & BsmtFinType2
- Description : Refers to walkout or garden level walls and Rating of basement finished area
- Process : In this case, the missing values are a house without a basement.
all_data['BsmtExposure']=all_data['BsmtExposure'].fillna('None')
all_data['BsmtFinType1']=all_data['BsmtFinType1'].fillna('None')
all_data['BsmtFinType2']=all_data['BsmtFinType2'].fillna('None')
BsmtFullBath & BsmtHalfBath
- Description : Basement full and half bathrooms
- Process : Missing values mean there is no bath so fill them with 0
all_data['BsmtHalfBath'] = all_data['BsmtHalfBath'].fillna(0)
all_data['BsmtFullBath'] = all_data['BsmtFullBath'].fillna(0)
Electrical
- Description : Electrical system
- Process : Approximately 92% of the data is SBrkr. Fill Missing Data with mode value(SBrkr)
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
Utilities
- Description : Type of utilities available
- Process : Since 100% of the test data is composed of AllPub, it is judged that there is no big meaning. So drop the column out
all_data.drop(['Utilities'], axis=1, inplace=True)
MSZoning
- Description : Identifies the general zoning classification of the sale
- Process : More than 78% of the data is made up of RL, so the missing values are processed using the mode value.
all_data['MSZoning']=all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
MasVnrArea
- Description : Masonry veneer area in square feet
- Process : About 60% of the data is 0, and it is thought that it is not decorated.
all_data['MasVnrArea']=all_data['MasVnrArea'].fillna(0)
MasVnrType
- Description : Masonry veneer type
- Process : Approximately 60% of the data is missing, meaning that it is not decorated.
all_data['MasVnrType']=all_data['MasVnrType'].fillna('None')
GarageType
- Description : Garage location
- Process : Attchd, Detchd, BuiltIn, Basment, 2Types, CarPort There are 6 categories, where missing value represents the house without garage and converts it to None value.
all_data['GarageType']=all_data['GarageType'].fillna('None')
GarageYrBlt
- Description : Year garage was built
- Process : Since the garage construction year is usually the same as the construction year, the Nan value is to be filled with the construction year
all_data['GarageYrBlt'][all_data['GarageYrBlt']>2150]
all_data['GarageYrBlt']=all_data['GarageYrBlt'].fillna(all_data['YearBuilt'][ all_data['GarageYrBlt'].isnull()])
GarageFinish, GarageCond, GarageQual
- Description : Garage Quality Related Categories
- Process : Features are all similar data and have the same number of missing values. Missing values are those without garage and are treated as None values.
all_data['GarageFinish']=all_data['GarageFinish'].fillna('None')
all_data['GarageCond']=all_data['GarageCond'].fillna('None')
all_data['GarageQual']=all_data['GarageQual'].fillna('None')
LotFrontage
- Description : Linear feet of street connected to property
- Process : Group the Neighborhood and treat it as a median in the same Neighborhood
all_data["LotFrontage"] = all_data.groupby("Neighborhood")["LotFrontage"].transform(lambda x: x.fillna(x.median()))
FireplaceQu
- Description : Fireplace quality
- Process : Missing value indicates that there is no fireplace and it is converted to None value.
all_data['FireplaceQu']=all_data['FireplaceQu'].fillna('None')
Fence
- Description : Fence quality
- Process : Missing values are fence-less, and convert to None
all_data['Fence']=all_data['Fence'].fillna('None')
Alley
- Description : Type of alley access to property
- Process : Grvl, and Pave. The missing values indicate that there are no adjacent alleys, and are converted to None values
all_data['Alley']=all_data['Alley'].fillna('None')
Functional
Description : Home functionality (Assume typical unless deductions are warranted)
Process : Since more than 93% of the total data is in the Typ format, the missing values are expected to be included in these functions
all_data['Functional']= all_data["Functional"].fillna("Typ")
MiscFeature
- Description : Miscellaneous feature not covered in other categories
- Process : The missing values are houses that do not contain these features, so replace them with none
all_data['MiscFeature']=all_data['MiscFeature'].fillna('None')
PoolQC
- Description : Pool quality
- Process : The missing values are houses that do not contain a pool, so replace them with none
all_data['PoolQC']=all_data['PoolQC'].fillna('None')
Exterior1st & Exterior2nd
- Description : Exterior covering on house
- 처리 방법 : 대부분의 외장재가 VinylSd로 되어있어 VinylSd로 예측 nan값을 mode로 채워줌
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
3-2 Feature Correlation¶
3-2-1 Numerical Features¶
To explore the features, we will use Correlation matrix (heatmap style).
corrmat = train.corr()
f, ax = plt.subplots(figsize = (15,9))
sns.heatmap(corrmat, vmax = 1, square=True)

This heatmap is the best way to get a quick overview of features relationships. At first sight, there are two red colored squares that get my attention. The first one refers to the 'TotalBsmtSF' and '1stFlrSF' variables, and the second one refers to the 'GarageX' variables. Both cases show how significant the correlation is between these variables. Actually, this correlation is so strong that it can indicate a situation of multicollinearity. If we think about these variables, we can conclude that they give almost the same information so multicollinearity really occurs.
'SalePrice' correlation matrix (High rank 15)
# 'SalePrice correlation (High rank 15)
# k is number of variables
k = 15
cor_numerical_cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
print("Numerical Features Qty :" ,len(cor_numerical_cols), "\n")
print("Numerical Features : \n",list(cor_numerical_cols))
Comments :¶
- There are many strong correlations between SalePrice and variables. OverallQual and GrLivArea are strongly correlated with SalePrice.
3-2-2 Categorical Features¶
# Select categorical features from train set
train_cat = train[categorical_features]
y_train_d = train['SalePrice']
# Dummy of category data
train_cat_dummies = pd.get_dummies(train_cat)
# Concatenate dummied categorical data with SalePrice
train_cat = pd.concat([y_train_d, train_cat_dummies], axis=1)
corrmat2 = train_cat.corr()
# High correlation coefficient 10
k = 10
cor_categorical_cols = corrmat2.nlargest(k, 'SalePrice')['SalePrice'].index
cor_categorical_cols
3-3 Determination of outliers and variables using OLS model¶
OLS (Ordinary least squares ) :¶
OLS is a method for estimating the unknown parameters in a linear regression model. OLS chooses the parameters of a linear function of a set of explanatory variables by minimizing the sum of the squares of the differences between the observed dependent variable (values of the variable being predicted) in the given dataset and those predicted by the linear function.
3-3-1 Model by all numerical Features¶
# Prepare train and test set
train = all_data[:ntrain]
test = all_data[ntrain:]
# Add_constant
train = sm.add_constant(train)
train.tail()
# Create train data with numerical features
train_n = train[numerical_features]
# Drop Id and SalePrice of data with numerical features
train_n = train_n.drop(['Id', 'SalePrice'], axis=1)
# Normalization by applying log to SalePrice
y_train_l = np.log1p(y_train_d)
# Apply to OLS model and save as model1_1
model1_1 = sm.OLS(y_train_l, train_n)
result1_1 = model1_1.fit()
3-3-2 Model by all categorical Features¶
# Excludes Utilities
categorical_features = ['MSSubClass', 'MSZoning', 'Street', 'Alley', 'LotShape', 'LandContour', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual', 'Functional', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence', 'MiscFeature', 'SaleType', 'SaleCondition']
# Convert data from categorical features into dummies
train_c = pd.get_dummies(train[categorical_features])
train_c.tail()
# Apply to OLS model and save as model1_2
model1_2 = sm.OLS(y_train_l, train_c)
result1_2 = model1_2.fit()
3-3-3 Model by numerical and categorical features together¶
# Concatenate numerical and categorical(dummy) data
train_all = pd.concat([train_n, train_c], axis=1)
train_all.tail()
# Apply to OLS model and save as model1_3
model1_3 = sm.OLS(y_train_l, train_all)
result1_3 = model1_3.fit()
3-3-4 Model by high correlation coefficient numerical features with SalePrice (Top 14)¶
# Storing 14 numerical variables with high correlation coefficients
cor_numerical_cols = ['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea',
'TotalBsmtSF', '1stFlrSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt',
'YearRemodAdd', 'GarageYrBlt', 'MasVnrArea', 'Fireplaces',
'BsmtFinSF1']
# Create data using 14 numerical variables
train_nc = train[cor_numerical_cols]
train_nc.tail()
# Apply to OLS model and save as model1_4
model1_4 = sm.OLS(y_train_l, train_nc)
result1_4 = model1_4.fit()
3-3-5 Model by high correlation coefficient numerical features (14 EA) and categorical features (5 EA)¶
# Create data using 5 categorical variables
cor_categorical_cols = ['Neighborhood', 'ExterQual', 'KitchenQual',
'BsmtQual', 'PoolQC']
train_cc = train[cor_categorical_cols]
# Concatenate numerical and categorical data
train_all_c = pd.concat([train_nc, train_cc], axis=1)
train_all_c.tail()
# Dummy categorical data and add constant
train_all_c = pd.get_dummies(train_all_c)
train_all_c = sm.add_constant(train_all_c)
train_all_c.tail()
# Apply to OLS model and save as model1_5
model1_5 = sm.OLS(y_train_l, train_all_c)
result1_5 = model1_5.fit()
3-3-6 Multi-collinearity and variance analysis between variables¶
(1) Multi-collinearity¶
- Multicollinearity refers to the case where a part of the independent variable can be represented by a combination of other independent variables. This occurs when the independent variables are not independent of each other but have strong mutual correlation.
- If there is multicollinearity, the conditional number of the covariance matrix of the independent variable increases
- VIF (Variance Inflation Factor) is used as a method of selecting interdependent independent variables. It can be seen that the higher the number, the more dependent on other variables $$ \text{VIF}_i = \frac{\sigma^2}{(n-1)\text{Var}[X_i]}\cdot \frac{1}{1-R_i^2} $$
# Create VIF dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(train_all_c.values, i) for i in range(train_all_c.values.shape[1])]
vif["features"] = train_all_c.columns
vif.sort_values("VIF Factor", ascending = True).head(20)
Comment :¶
- Multilinearity between variables extracted except for categorical features is low.
(2) Analysis of variance on categorical features¶
- Analysis of variance (ANOVA) is a method to evaluate the performance of linear regression analysis using the relationship between the variance of dependent variables and the variance of independent variables
- The analysis of variance can be applied to the performance comparison of two different linear regression analyzes. It can also be used to quantitatively analyze the effect of each category value when the independent variable is a category variable
- TSS : Range of movement of dependent variable values
- ESS : Range of predictive bass movements from model
RSS : The range of motion of residuals, that is the magnitude of the error
$$ \dfrac{\text{ESS}}{K-1} \div \dfrac{\text{RSS}}{N-K} = \dfrac{R^2/(K-1)}{(1-R^2)/(N-K)} \sim F(K-1, N-K) $$
- Variance analysis table

# Anova test : Neighborhood
model_cat = sm.OLS.from_formula("SalePrice ~ C(Neighborhood)", data=train)
sm.stats.anova_lm(model_cat.fit())
# Anova test : ExterQual
model_cat = sm.OLS.from_formula("SalePrice ~ C(ExterQual)", data=train)
sm.stats.anova_lm(model_cat.fit())
# Anova test : KitchenQual
model_cat = sm.OLS.from_formula("SalePrice ~ C(KitchenQual)", data=train)
sm.stats.anova_lm(model_cat.fit())
# Anova test : BsmtQual
model_cat = sm.OLS.from_formula("SalePrice ~ C(BsmtQual)", data=train)
sm.stats.anova_lm(model_cat.fit())
# Anova test : PoolQC
model_cat = sm.OLS.from_formula("SalePrice ~ C(PoolQC)", data=train)
sm.stats.anova_lm(model_cat.fit())
Comments :¶
- Anova test shows that the five category variables are significant
3-3-7 Comparison of model performance by using variables¶
1) $R_{adj}^2$ Performance
In the linear regression model, the value of the coefficient of determination $( R^2 )$ always increases when an independent variable is added
The coefficient that adjusts the value of the decision coefficient according to the number of independent variables K to offset the effect of addition of independent variables. The closer to 1, the better the model $$ R_{adj}^2 = 1 - \frac{n-1}{n-K}(1-R^2) = \dfrac{(n-1)R^2 +1-K}{n-K} $$
print("result1_1.rsquared_adj :", result1_1.rsquared_adj)
print("result1_2.rsquared_adj :", result1_2.rsquared_adj)
print("result1_3.rsquared_adj :", result1_3.rsquared_adj)
print("result1_4.rsquared_adj :", result1_4.rsquared_adj)
print("result1_5.rsquared_adj :", result1_5.rsquared_adj)
2) AIC (Akaike Information Criterion) Performance
- The AIC maximizes the Kullback-Leibler level between the probability distribution of the model and the data, and the smaller the value, the closer to the good model
$$ \text{AIC} = -2\log L + 2K \ $$
print("result1_1.aic :", result1_1.aic)
print("result1_2.aic :", result1_2.aic)
print("result1_3.aic :", result1_3.aic)
print("result1_4.aic :", result1_4.aic)
print("result1_5.aic :", result1_5.aic)
3) BIC(Bayesian Information Criterion) Perfomance
- BIC is derived from the value for measuring the model likelihood in the given data under the assumption that the data is an exponential family. The smaller the value, the closer to the good model
$$ \text{BIC} = -2\log L + K\log n\ $$
print("result1_1.bic :", result1_1.bic)
print("result1_2.bic :", result1_2.bic)
print("result1_3.bic :", result1_3.bic)
print("result1_4.bic :", result1_4.bic)
print("result1_5.bic :", result1_5.bic)
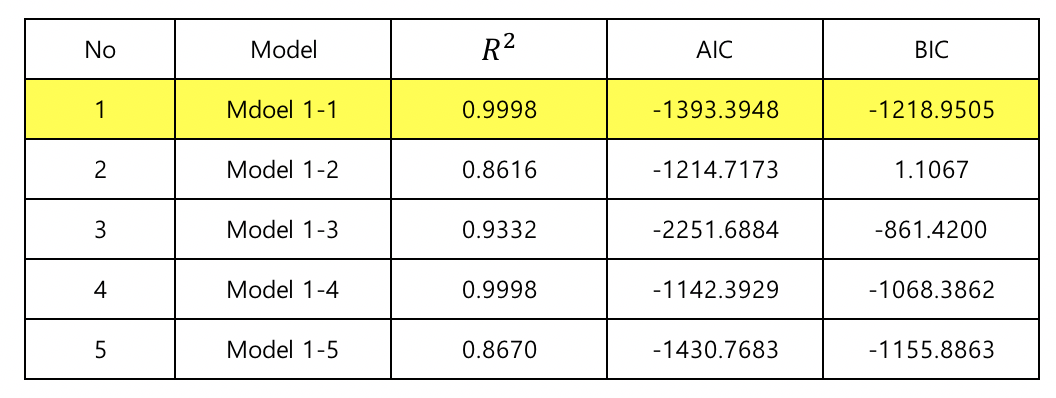
Comment :¶
- Adj. $R^2$: Models 1 and 4 are the highest with 0.99 and have similar performance
- AIC : Models 1 and 3 are low
- BIC : Models 1 and 3 are low
- In conclusion, future model verification will be based on model 1
3-4 Outlier¶
1) Option1 : IQR (Interquartile Range)
- IQR : Difference between quartile (Q3) and quartile (Q1) (Q3 - Q1)
- Box-Whisker Plot outer vertical line represents 1.5 X IQR and the out-of-line point is called the outlier.
# IQR Outlier function
def detect_outliers(data, feature):
Q1 = np.percentile(data[feature], 25)
Q3 = np.percentile(data[feature], 75)
IQR = Q3 - Q1
# Outer vertical line represents 1.5 X IQR
outlier_length = 1.5 * IQR
outliers = data[(data[feature] < Q1 - outlier_length) | (data[feature] > Q3 + outlier_length)].index.tolist()
return outliers
# Detect outlier from GrLivArea, OverallQual, GarageArea
GrLivArea_outliers = detect_outliers(train, "GrLivArea")
OverallQual_outliers = detect_outliers(train, "OverallQual")
GarageCars_outliers = detect_outliers(train, "GarageArea")
2) Option2 : Standardized resids
- The residuals are divided by the standard deviation of the leverage and residuals and scaled to have the same standard deviation are called standardized residuals or normalized residuals
$$ r_i = \dfrac{e_i}{s\sqrt{1-h_{ii}}} $$
- The standardization residual using the resid_pearson property of the RegressionResult of StatsModels. If it is larger than 2 ~ 4, it is called outlier.
# Model1_1 uses the standardized residual attribute for the output, and assigns an outlier larger than 2
idx_r = np.where(result1_1.resid_pearson > 2)[0]
3) Option3 : Cook's Distance
- If both the leverage and the residual size increase, Cook's Distance also increases.
$$ D_i = \frac{r_i^2}{\text{RSS}}\left[\frac{h_{ii}}{(1-h_{ii})^2}\right] $$
Fox 'Outlier Recommendation is judged as an outlier when Cook's Distance is larger than the following reference value
$$ D_i > \dfrac{4}{N − K - 1} $$
# Designated outliers using Fox 'Outlier Recommendation on the output from model1_1
influence = result1_1.get_influence()
cooks_d2, pvals = influence.cooks_distance
fox_cr = 4 / (len(y_train_l) - len(train_n.columns) - 1)
idx_c = np.where(cooks_d2 > fox_cr)[0]
4) Check all outliers (option 1,2,3)
resid_outliers = idx_r.tolist()
cooks_outliers = idx_c.tolist()
print("resid_outliers:", len(resid_outliers),"개 \n", resid_outliers)
print("\t")
print("cooks_outliers:", len(cooks_outliers),"개 \n", cooks_outliers)
print("\t")
print("(IQR)GrLivArea_outliers:", len(GrLivArea_outliers),"개 \n", GrLivArea_outliers)
print("\t")
print("(IQR)OverallQual_outliers", len(OverallQual_outliers),"개 \n", OverallQual_outliers)
print("\t")
print("(IQR)GarageCars_outliers:", len(GarageCars_outliers),"개 \n", GarageCars_outliers)
#제거하길 추천한 outliers(data description)
# recommended_outliers = [523, 898, 1298]
5) Combination of outliers groups
- IQR [ GrLivArea_outliers , OverallQual_outliers, GarageCars_outlier ] [used option1 outlier]
IQR = list(set(GrLivArea_outliers) | set(OverallQual_outliers) | set(GarageCars_outliers))
print("IQR outliers :", len(IQR),"개 \n", IQR)
- IQR2 [ GrLivArea_outliers, GarageCars_outlier ] [used option1 outlier]
IQR2 = list(set(GrLivArea_outliers) & set(GarageCars_outliers))
print("IQR2 outliers :", len(IQR2),"개 \n", IQR2)
- Resid & Cook distance [used option2 + option3 outlier]
resid_cooks = list(set(resid_outliers) | set(cooks_outliers))
print("Resid_Cooks_distance :", len(resid_cooks ),"개 \n", resid_cooks)
- IQR & Resid & Cook distance [combine option1 + option2 + option3 outlier]
resid_cooks_IQR = list(set(resid_cooks) | set(IQR))
print("Resid_Cooks_IQR :", len(resid_cooks_IQR),"개 \n", resid_cooks_IQR)
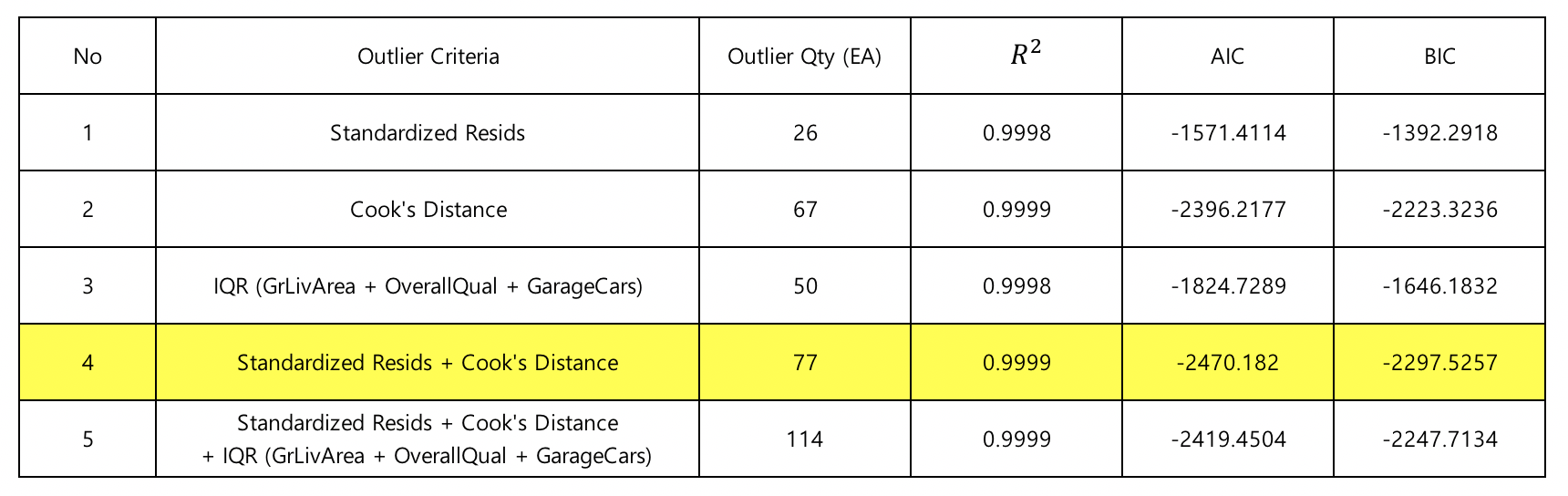
Comments :¶
Based on the selected outliers, create a number of 5 cases and turn them on Model_1.
As a result of comparing the performance, we used outlier based on resid and cook's distance
3-5 Data preprocessing¶
3-5-1 Select numerical variables¶
- Numeric_variable_select_1 : Select the variable whose P-value is 0.05 or less among the result values of Model_1.
# A variable whose P-value is 0.05 or less among the result values of Model_1 are selected
idx_t = np.where(result1_1.pvalues < 0.05)[0]
p_values = idx_t.tolist()
# Change index value to column name
x_train_cols = train_n.columns.tolist()
numeric_variable_select_1 = []
for i in p_values:
numeric_variable_select_1.append(x_train_cols[i])
# Except for PoolArea, 1stFlrArea with many none values and scale error
numeric_variable_select_1 = ['LotArea', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'BsmtFinSF1', 'TotalBsmtSF', 'GrLivArea', 'BsmtFullBath', 'FullBath', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'WoodDeckSF', 'EnclosedPorch', 'ScreenPorch', 'YrSold']
print("Variables Qty [The P-value of the result of Model_1 is less than 0.05] :",len(numeric_variable_select_1),"EA\n\n", \
"Variables [The P-value of the result of Model_1 is less than 0.05] :","\n",numeric_variable_select_1)
- Numeric_variable_select_2 : Select variable based on VIF factor during numeric_variable_select_1
# Check VIF of numeric_variable_select_1
x_train_new = train[numeric_variable_select_1]
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x_train_new.values, i) for i in range(x_train_new.values.shape[1])]
vif["features"] = x_train_new.columns
vif.sort_values("VIF Factor", ascending = True)
# Except TotRmsAbvGrd, Yearsold, YearRemodAdd due to high multi-collinearity
numeric_variable_select_2 = ['LotArea', 'OverallCond', 'YearBuilt', 'BsmtFinSF1', 'TotalBsmtSF', 'GrLivArea', 'BsmtFullBath', 'FullBath', 'KitchenAbvGr', 'Fireplaces', 'GarageCars', 'WoodDeckSF', 'EnclosedPorch', 'ScreenPorch', 'OverallQual']
print("Number of variables with low multicollinearity :",len(numeric_variable_select_2),"EA\n\n", \
"Variables with low multicollinearity :","\n",numeric_variable_select_2)
- numeric_variable_select_3 : 14 variables with high correlation coefficient
numeric_variable_select_3 = ['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF', 'FullBath', 'YearBuilt', 'GarageYrBlt', 'MasVnrArea', 'Fireplaces', 'BsmtFinSF1']
print("Number of variables with high correlation coefficient :",len(numeric_variable_select_3),"EA\n\n", \
"Variables with high correlation coefficient:","\n",numeric_variable_select_3)
- numeric_variable_select_4 : The union variable of numeric_variable_select_2 and numeric_variable_select_3
numeric_variable_select_4= ['GarageYrBlt', 'GarageCars', 'LotArea', 'YearBuilt', 'WoodDeckSF', 'MasVnrArea', 'KitchenAbvGr', 'TotalBsmtSF', 'BsmtFullBath', 'EnclosedPorch', 'ScreenPorch', 'GarageArea', 'BsmtFinSF1', 'Fireplaces', 'GrLivArea', 'FullBath', 'OverallQual', 'OverallCond']
print("Number of the union variable of numeric_variable_select_2 and numeric_variable_select_3 :",len(numeric_variable_select_4),"EA\n\n", \
"The union variable of numeric_variable_select_2 and numeric_variable_select_3 :","\n",numeric_variable_select_4)
- numeric_variable_select_5 : Select variable based on VIF factor among numeric_variable_select_4
# Check VIF for numeric_variable_select_4
x_train_new = train_n[numeric_variable_select_4]
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x_train_new.values, i) for i in range(x_train_new.values.shape[1])]
vif["features"] = x_train_new.columns
vif.sort_values(by="VIF Factor", ascending=True)
# Except GarageArea, GarageYrBlt due to high multi-collinearity
numeric_variable_select_5 = ['GarageCars', 'LotArea', 'YearBuilt', 'WoodDeckSF', 'MasVnrArea', 'KitchenAbvGr', 'TotalBsmtSF', 'BsmtFullBath', 'EnclosedPorch', 'ScreenPorch', 'BsmtFinSF1', 'Fireplaces', 'GrLivArea', 'FullBath', 'OverallQual', 'OverallCond']
print("Number of variables with low VIF factor among numeric_variable_select_4 :",len(numeric_variable_select_5),"개\n\n", \
"Variables with low VIF factor among numeric_variable_select_4 :","\n",numeric_variable_select_5)
3-5-2 Select categorical variables¶
- Categorical_variable_select_1 : The 5 variables with high correlation coefficients used in Model_5, excluding PoolQC
categorical_variable_select_1 = ['Neighborhood', 'ExterQual', 'KitchenQual', 'BsmtQual']
print("Number of variables with high correlation coefficient :",len(categorical_variable_select_1),"EA\n\n", \
"Variables with high correlation coefficient :","\n", categorical_variable_select_1)
- categorical_variable_select_2 : Select the variable whose P-value is less than 0.005 among the result values of Model_3.
# Excluding 'Condition2', 'RoofMatl', and 'Functional' in category variables
categorical_variable_select_2 = ['MSZoning', 'Neighborhood']
print("Number of variables [The P-value of the result of Model_3 is less than 0.05] :",len(categorical_variable_select_2),"EA\n\n", \
"Variables [The P-value of the result of Model_3 is less than 0.05] :","\n",categorical_variable_select_2)
- categorical_variable_select_3 : The union variable for categorical_variable_select_1 and categorical_variable_select_2
categorical_variable_select_3 = ['Neighborhood', 'ExterQual', 'KitchenQual', 'BsmtQual', 'MSZoning']
print("Number of the union variable for categorical_variable_select_1 and categorical_variable_select_2 :",len(categorical_variable_select_3),"EA\n\n", \
"The union variable for categorical_variable_select_1 and categorical_variable_select_2 :","\n", categorical_variable_select_3)
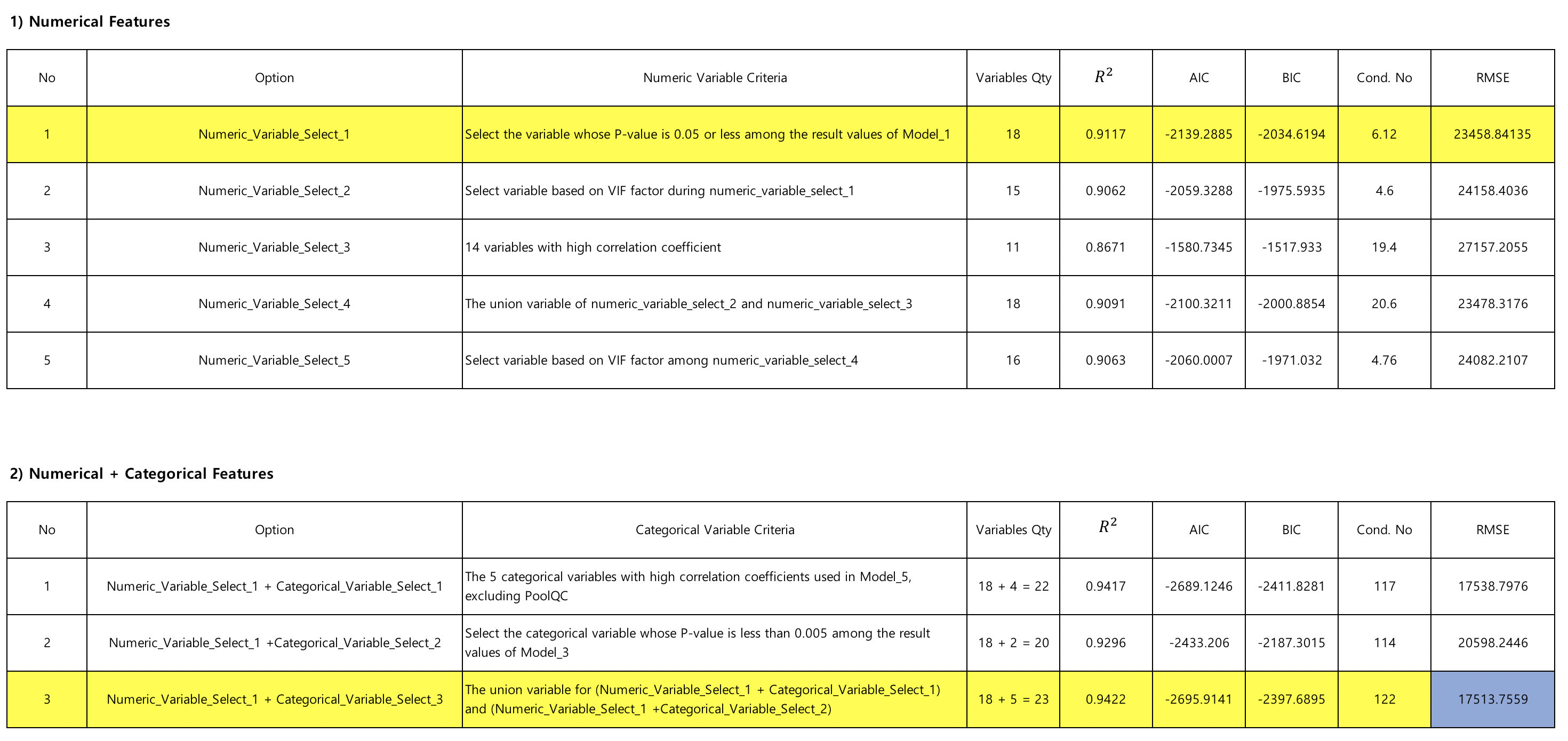
Comment :¶
Turn numerical variables first and compare performance
Fix the best variable among the numerical variables, add the categorical variables, and compare
Performance with numeric_variable_select_1 and categorical_variable_select_3 together turned out to be the best
4. Model¶
4-1 Input data¶
# Remove outliers after selecting variables
train_n = train_n[numeric_variable_select_1]
train_n = train_n.drop(resid_cooks)
train_c = train[categorical_variable_select_3]
train_c = train_c.drop(resid_cooks)
# Numerical variable log conversion
train_n = np.log1p(train_n)
# numerical + categorical
x_train_new = pd.concat([train_n, train_c], axis=1)
# Remove SalePrice Outlier
y_train_new = y_train_d.drop(resid_cooks)
# SalePrice log conversion
y_train_new = np.log1p(y_train_new)
# Make data
train_new = pd.concat([y_train_new, x_train_new], axis=1)
train_new.tail()
# In the OSL model, a scale is added to the variable name
select_scale = []
for num in numeric_variable_select_1:
x = "scale(" + num + ")"
select_scale.append(x)
formula = " + ".join(select_scale)
formula
# To scale the categorical variables in the OSL model, add a scale to the variable name
c_categorical = []
for num in categorical_variable_select_3:
x = "C(" + num + ")"
c_categorical.append(x)
formula = " + ".join(c_categorical)
formula
4-2 OLS(Ordinary Least Square) Model¶
4-2-1 Make OLS Model¶
# Input data into OLS model
model2_1 = sm.OLS.from_formula("SalePrice ~ scale(LotArea) + scale(OverallQual) + scale(OverallCond) + scale(YearBuilt) + scale(YearRemodAdd) + scale(BsmtFinSF1) + scale(TotalBsmtSF) + scale(GrLivArea) + scale(BsmtFullBath) + scale(FullBath) + scale(KitchenAbvGr) + scale(TotRmsAbvGrd) + scale(Fireplaces) + scale(GarageCars) + scale(WoodDeckSF) + scale(EnclosedPorch) + scale(ScreenPorch) + scale(YrSold)+C(Neighborhood) + C(ExterQual) + C(KitchenQual) + C(BsmtQual) + C(MSZoning)", data=train_new)
result2_1 = model2_1.fit()
print(result2_1.summary())
print("rsquared_adj :", result2_1.rsquared_adj)
print("AIC :", result2_1.aic)
print("BIC :", result2_1.bic)
Comments :¶
- $R_{adj}^2$ value is close to 1 but residual normality does not represent normality
- The P-value of the numeric variable is less than 0.05, which is a significant variable.
- AIC and BIC should be low, but if negative, verification is required
4-2-2 ANOVA F-test¶
- ANOVA F test can compare the importance of each independent variables
- Method : The influence of each independent variable is indirectly measured by comparing the performance of the model minus the whole model and only one of the variables.
- The lower the value of PR (> F), the higher the importance
sm.stats.anova_lm(result2_1, typ=2)
Comments :¶
- GrLivArea (living room width), which has the lowest PR (> F) of all variables, has the greatest influence on the house value
- TotRmsAbvGrd (room quality), which has a relatively high PR (> F), has a small effect on house values
4-2-3 RMSE¶
- Use statsmodels.tools.eval_measures.rmse to compare actual SalePrice to SalePrice predicted by OLS
# Drop SalePrice from dataframe
train_new2 = train_new.drop(['SalePrice'], axis=1)
# Predict train's Saleprice
y_train_new2 = result2_1.predict(train_new2)
y_train_new2 = np.exp(y_train_new2)
y_train_new2 = np.array(y_train_new2)
# Actual Saleprice
y_train_new_a = np.array(y_train_new)
y_train_new = np.exp(y_train_new_a)
# Comparison of actual SalePrice and SalePrice predicted by OLS
print("RMSE :", sm.tools.eval_measures.rmse(y_train_new, y_train_new2, axis=0))
4-2-4 Normalization of residuals¶
- According to the probabilistic linear regression model, the residuals in the regression analysis [$e = y - \hat{w}^Tx$] follow the normal distribution
# Check the chi-squared and p-value of the residuals of the OLS model
test_norm = sms.omni_normtest(result2_1.resid)
for xi in zip(['Chi^2', 'P-value'], test_norm):
print("%-12s: %6.3f" % xi)
# Check the residual of OLS model with QQ Plot
sp.stats.probplot(result2_1.resid, plot=plt)
plt.show()

Comments :¶
- The residuals of the OLS model do not follow normality numerically, but if we look at the Probability Plot we can see that it is close to a straight line
4-3 Predict SalePrice¶
# Select test data using numerical variables
test_new = test[numeric_variable_select_1]
# Normalization of numerical data of test data
test_new = np.log1p(test_new)
# Select test data using categorical variables
test_new2 = test[categorical_variable_select_3]
# combine the data
test_new = pd.concat([test_new, test_new2], axis=1)
test_new.tail()
# Input test data processed in OLS model
y_new = result2_1.predict(test_new)
# Exponentional conversion of predicted test data values to actual prices
y_new = np.exp(y_new)
# Converted to an array format to write predicted values to the csv file for submission
y_new = np.array(y_new)
print(y_new)
# Import sample file
submission = pd.read_csv("../1_House_Price_Project_X/Submit/sample_submission.csv")
# Write the predicted price in the SalePrice of the sample file
submission["SalePrice"] = y_new
# Check the sample file that was written
print(submission.shape)
submission.head()
# Output to csv file format
submission.to_csv("1_submission.csv", index=False)