📚 Amazon Bedrock 파인튜닝 & 모델 선택
1. 다양한 제공자와 모델 특징
- 대표 제공자(Providers): Anthropic, Amazon, DeepSeek, Stability AI 등
- 각 모델마다 잘하는 분야가 다름:
- Claude 3.5 Haiku → 텍스트 처리에 최적화
- Amazon Nova Reel → 텍스트-영상, 이미지-영상 변환
- 💡 시험 포인트: 시험에서 “어떤 모델이 제일 좋은가?”를 묻지 않음 → 각 모델이 할 수 있는 것과 못 하는 것만 구분
2. 모델 비교하기
- Bedrock Playground에서 여러 모델을 나란히 테스트 가능
- 비교 기준:
- ✅ 지원 기능 (텍스트, 이미지, 비디오)
- ✅ 출력 스타일/형식
- ✅ 속도(지연 시간)
- ✅ 비용(토큰 사용량)
- 예시:
- Nova Micro → 이미지 업로드 불가 ❌, 대신 빠르고 간단한 답변
- Claude 3.5 Sonnet → 이미지 지원 가능 ✅, 길고 상세한 답변

3. 파인튜닝 방법 비교 (시험 자주 출제!)
| 구분 | Instruction-Based Fine-Tuning | Continued Pre-Training | Transfer Learning |
|---|---|---|---|
| 데이터 유형 | 라벨링된 데이터 (프롬프트–응답 쌍) | 라벨링 안 된 원본 텍스트 | 라벨링/비라벨링 모두 가능 |
| 목표 | 특정 태스크/톤/스타일 맞춤 | 특정 도메인 전문화 | 다른 유사한 태스크로 전이 |
| 예시 | 특정 톤으로 대답하는 챗봇 | AWS 문서 전체 학습 → AWS 전문가 모델 | 의료 분야 텍스트 분류 |
| 모델 가중치 변경? | ✅ 변경됨 | ✅ 변경됨 | ✅ 변경됨 |
| 복잡도 | 중간 | 높음 | 다양 |
| 비용 | 상대적으로 저렴 | 매우 비쌈 (데이터 많음) | 상황에 따라 다름 |
| 시험 키워드 | “라벨링 데이터”, “프롬프트–응답” | “비라벨링 데이터”, “도메인 적응” | “새로운 유사 태스크 적응” |
| Bedrock 지원 | 일부 모델 지원 | 일부 모델 지원 | 일반 ML 개념 (Bedrock 전용 아님) |
Instruction-based Fine Tuning

Continued Pre-training

4. 메시징 파인튜닝
- 단일 턴(Single-Turn): 질문 1개 → 답변 1개, 필요 시
system컨텍스트 추가

- 다중 턴(Multi-Turn): 대화처럼
user와assistant가 번갈아 대화 → 챗봇 훈련에 활용

5. 전이 학습 (Transfer Learning)
- 정의: 이미 학습된 모델을 새로운 유사한 작업에 활용
- 예시:
- 이미지 분류 (고양이 vs 강아지 → 꽃 분류)
- NLP 모델 (BERT, GPT) 재활용
- 💡 시험 팁:
- 일반 ML 문제 → Transfer Learning
- Bedrock 관련 → Fine-Tuning
6. Bedrock에서 파인튜닝 조건
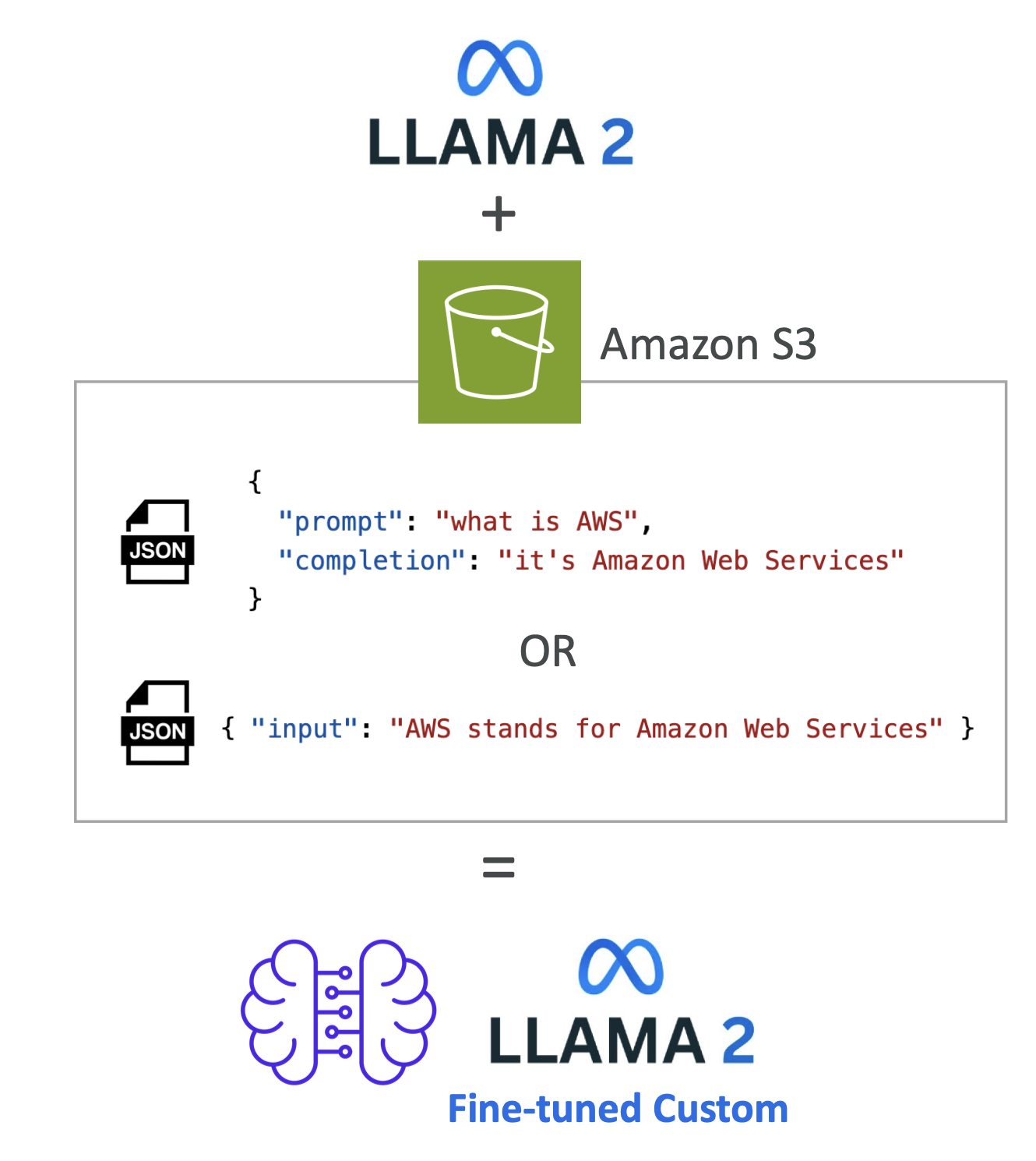
- 학습 데이터는 반드시:
- Amazon S3에 저장
- 정해진 포맷 준수
- Provisioned Throughput 필요:
- 커스텀 모델 생성 시
- 커스텀 모델 사용 시

- 모든 모델이 파인튜닝 가능한 건 아님 → 주로 오픈소스 모델 지원
7. 파인튜닝 활용 사례
- 특정 톤/페르소나 챗봇 제작
- 최신 지식 반영
- 기업 내부 비공개 데이터 활용 (고객 로그, 내부 문서)
- 분류 정확도 향상, 응답 스타일 조정
8. 시험 팁 정리
- “라벨링 데이터” → Instruction-Based Fine-Tuning
- “비라벨링 데이터 / 도메인 적응” → Continued Pre-Training
- “새로운 유사 작업 적응” → Transfer Learning
- Bedrock에서 커스텀 모델 = Provisioned Throughput 필수
- 파인튜닝 = 모델 가중치 변경 → 내 전용 모델 생성
- 모델 비교 시 → 품질뿐 아니라 속도와 비용 고려
9. 추가로 알아두면 좋은 점
- FM 전체 재학습은 비용·시간 모두 매우 큼
- Instruction 기반 파인튜닝은 상대적으로 저렴 (적은 데이터, 적은 연산)
- 하지만 전문 ML 엔지니어 필요
- 과정: 데이터 준비 → 파인튜닝 → 모델 평가 → 운영
- 파인튜닝 모델 실행 시도 Provisioned Throughput 필요 → 비용 추가
10. Provisioned Throughput (중요 시험 포인트!)
- 정의: 커스텀 모델을 위한 전용 처리 용량 예약
- 필요 이유:
- 안정적 성능 보장
- 트래픽 증가 시 성능 저하 방지
- 예측 가능한 비용 관리
- 💡 시험 팁: Bedrock에서 커스텀 모델 = 무조건 Provisioned Throughput 필요
✅ 시험 핵심 요약표
| 구분 | 핵심 포인트 | 시험 키워드 |
|---|---|---|
| 모델 제공자 | Anthropic, Amazon, DeepSeek, Stability AI 등 | “어떤 모델이 제일 좋은가?” ❌, “할 수 있는 것/못하는 것” ✅ |
| 모델 비교 기준 | 기능(텍스트/이미지/비디오), 출력 스타일, 속도, 비용 | Compare Mode |
| Instruction-Based Fine-Tuning | 라벨링 데이터 필요 (프롬프트–응답 쌍), 비용 낮음, 특정 톤/스타일 맞춤 | Labeled data, Prompt–Response |
| Continued Pre-Training | 비라벨링 데이터로 도메인 전문화, 데이터·비용 큼 | Unlabeled data, Domain Adaptation |
| Transfer Learning | 기존 모델을 새로운 유사 작업에 적응 | Adapt model to new task |
| 메시징 파인튜닝 | 단일 턴(Single-Turn), 다중 턴(Multi-Turn) 지원 | Chatbot Training |
| Provisioned Throughput | 커스텀 모델 생성/운영 시 필수, 전용 처리 용량 예약 | Required for Bedrock Custom Models |
| 비용 절감 | Instruction-Based FT가 가장 저렴, Full FM 재학습은 비용 매우 큼 | Cost Optimization |
📌 추가 시험 포인트
- 파인튜닝은 모델 가중치를 변경하여 내 전용 모델을 만드는 것
- Bedrock은 모든 모델이 파인튜닝 가능한 건 아님 → 주로 오픈소스 모델 지원
- 커스텀 모델은 반드시 Provisioned Throughput 필요
- 모델 비교 시 속도와 비용도 중요
- Fine-Tuning 단계: 데이터 준비 → 학습 → 평가 → 운영
- 실행 비용은 일반 모델보다 높음 (전용 리소스 사용)
👉 결론:
Amazon Bedrock 파인튜닝 = 내 데이터로 맞춤형 모델을 만들 수 있는 기능
시험 핵심 = 키워드 매핑(라벨링 vs 비라벨링 vs 새로운 태스크) + Provisioned Throughput

Leave a comment