📚 Amazon Bedrock – RAG & Knowledge Base
1. 🔍 RAG란 무엇일까?
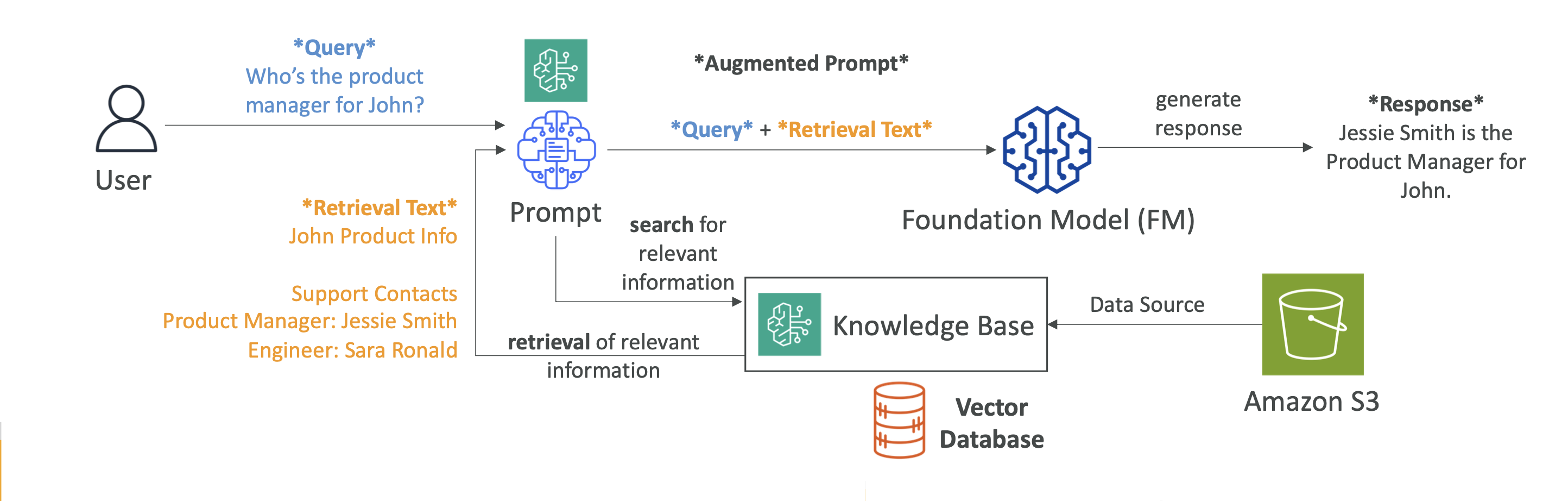
RAG (Retrieval-Augmented Generation) 은
외부 데이터에서 정보를 검색(Retrieve) 하고 → 이를 프롬프트에 추가(Augment) 하여 → 모델이 더 정확한 답변을 생성(Generate) 하는 방법이에요.
- 검색(Retrieval): 모델이 학습하지 못한 최신 데이터나 특정 도메인 데이터를 가져와요.
- 증강(Augmentation): 검색한 데이터를 질문과 합쳐서 모델에 전달해요.
- 장점: 모델을 새로 학습(Fine-tuning)하지 않고도 최신 지식을 반영할 수 있어요.
2. 🏗 동작 방식 (Step-by-Step)
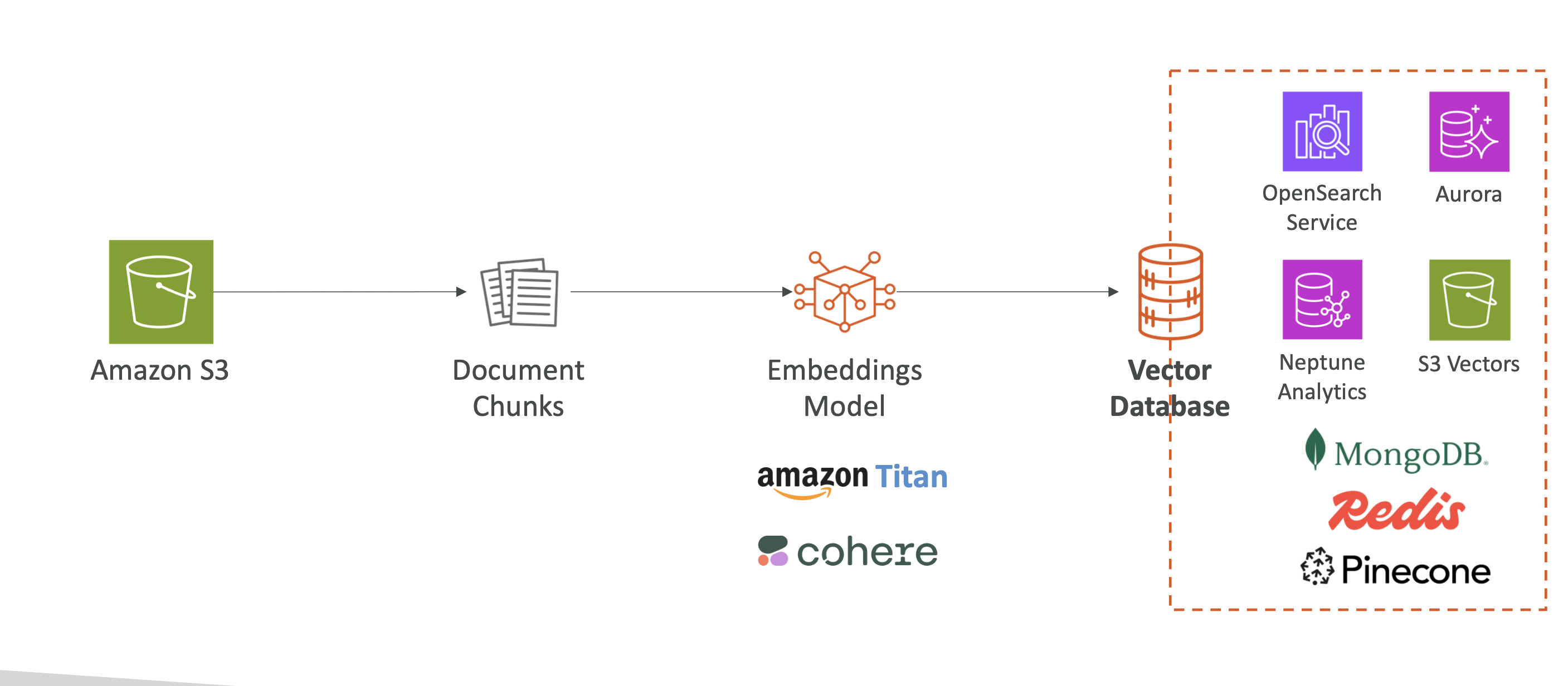
- 데이터 저장소
- Amazon S3, Confluence, SharePoint, Salesforce, 웹사이트 등에 문서를 저장
- 벡터 임베딩 생성
- Bedrock이 문서를 작은 조각으로 나누고
- Amazon Titan, Cohere 같은 임베딩 모델로 숫자 벡터로 변환
- 벡터 데이터베이스 저장
- 변환된 벡터를 OpenSearch, Aurora, Neptune, S3 Vectors 같은 벡터 DB에 저장
- 쿼리 처리
- 사용자가 질문하면 → 질문도 벡터로 변환 → DB에서 유사한 벡터 검색
- 프롬프트 증강
- 검색된 결과를 원래 질문과 합쳐서 모델에 전달
- 답변 생성
- Claude, Titan Text, Llama 같은 모델이 맥락을 이해하고 답변 + 출처 제공
3. 🛠 주요 구성 요소
| 구성 요소 | 설명 | AWS / 외부 옵션 |
|---|---|---|
| 데이터 소스 | 원본 데이터 저장 위치 | Amazon S3, Confluence, SharePoint, Salesforce, 웹사이트 |
| 임베딩 모델 | 텍스트를 벡터로 변환 | Amazon Titan, Cohere |
| 벡터 DB | 벡터 저장 및 검색 | OpenSearch, Aurora, Neptune, S3 Vectors / Pinecone, Redis, MongoDB |
| 기초 모델 | 최종 답변 생성 | Claude, Titan Text, Llama 등 |
4. 📊 AWS 벡터 DB 비교 (시험 포인트!)
| 서비스 | 특징 | 활용 사례 |
|---|---|---|
| OpenSearch | 실시간 검색, KNN 지원, 서버리스 모드 있음 | 대규모 실시간 검색 & 분석 |
| Aurora PostgreSQL | RDB에 벡터 검색 통합 (pgvector) | 기존 SQL 시스템에 RAG 결합 |
| Neptune Analytics | 그래프 기반 검색 (GraphRAG) | 관계 중심 데이터, 그래프 분석 |
| S3 Vectors | 저비용, 높은 내구성, 빠른 쿼리 | 장기 보관 및 비용 최적화 |
✅ 시험 꿀팁
- “실시간 대규모 검색” → OpenSearch
- “그래프 관계 중심” → Neptune
- “저비용/고내구성” → S3 Vectors
5. 📌 왜 KNN 검색이 중요한가?
RAG에서 KNN (k-Nearest Neighbors) 검색은 가장 중요한 단계예요.
- 문서와 질문을 벡터로 변환 → 서로의 “거리”를 계산 → 가장 가까운 k개 문서 검색
- 거리 계산 방법: 코사인 유사도(Cosine Similarity), 유클리드 거리 등
- AWS 시험에서는 “semantic search”, “vector similarity search” = KNN 검색을 의미한다고 보면 돼요.
- OpenSearch의 Approximate k-NN 은 대규모 실시간 검색에 자주 출제돼요.
6. 💡 대표적인 활용 사례
- 고객 서비스 챗봇 → 제품 매뉴얼, FAQ, 트러블슈팅 문서 기반 답변
- 법률 리서치 → 판례, 법령, 규제 문서를 검색해 정확한 출처와 함께 제공
- 헬스케어 Q&A → 질병, 치료, 연구 논문 데이터를 기반으로 답변
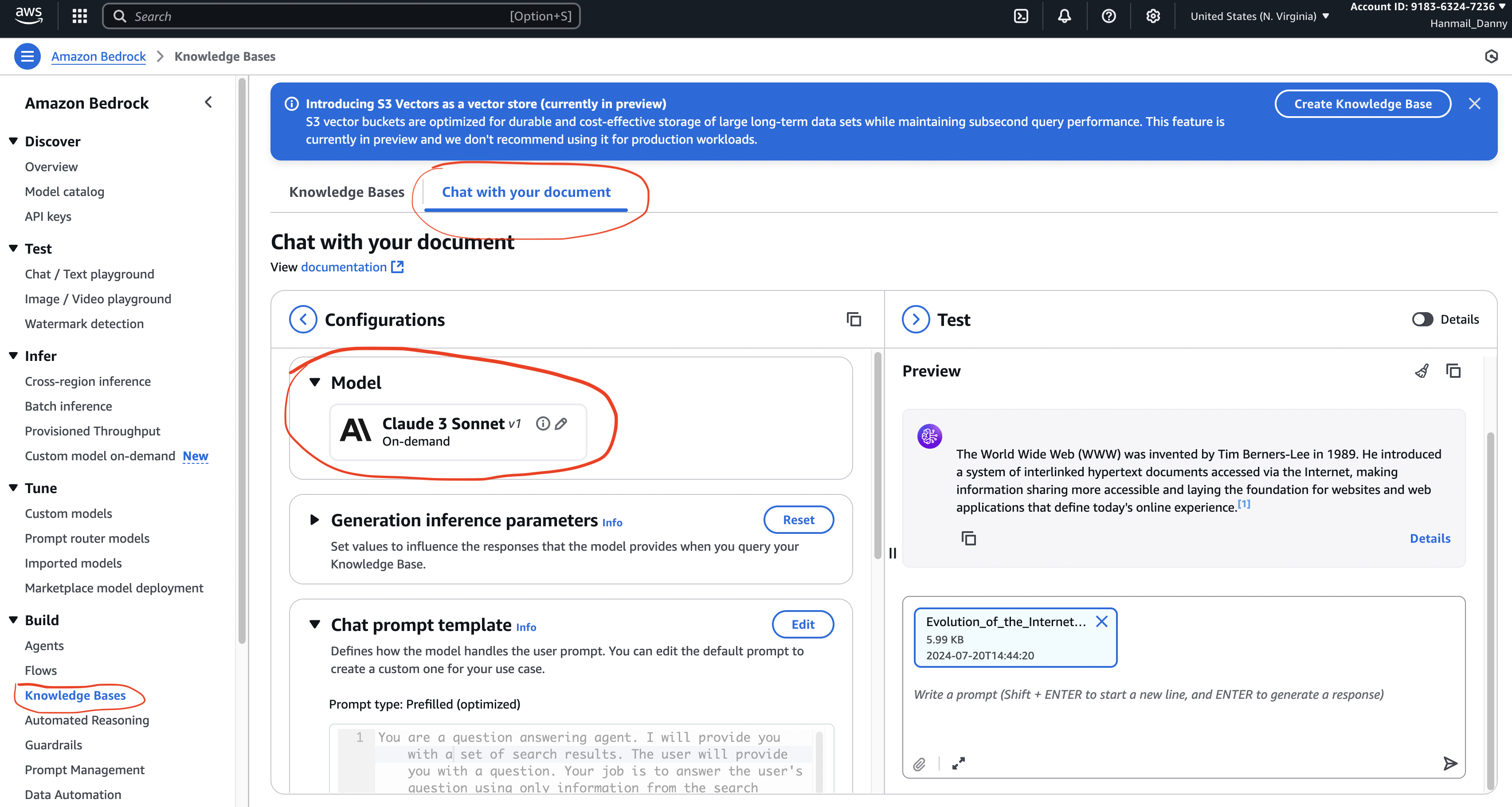
7. 🧪 실습 예시 – “내 문서와 대화하기”
- 목표: 업로드한 문서를 기반으로 질문-답변 챗봇 만들기
- 절차
- AWS Console → Knowledge Bases 이동
- “Chat with your document” 선택
- 문서 업로드
- 질문 입력 → 예: “WWW를 발명한 사람은 누구야?”
- 모델이 문서 검색 → 관련 문단 찾아서 답변 생성 (출처 포함)
<p align="center">
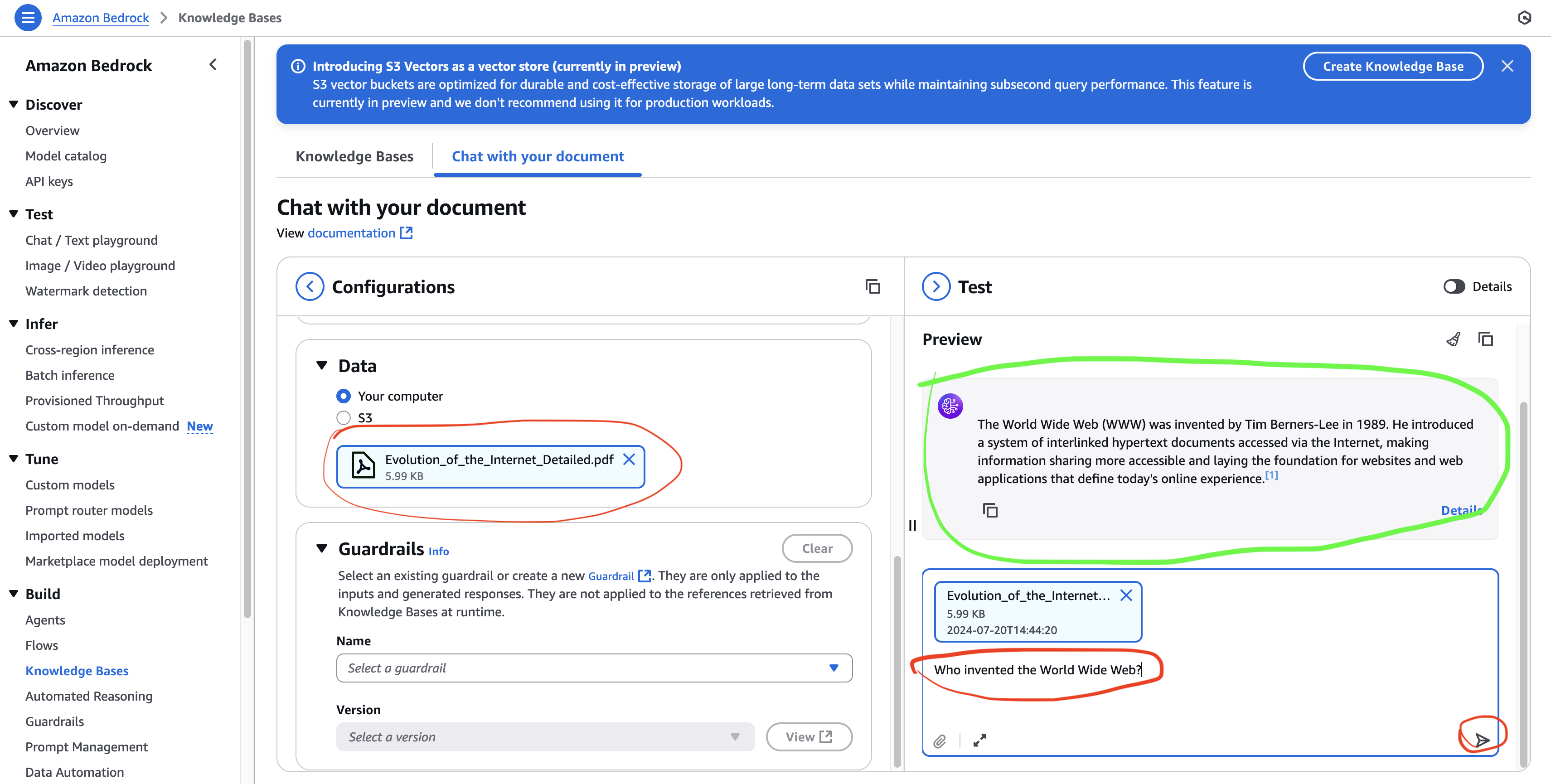
- 시험 팁: 답변할 데이터가 없을 땐 “제공된 데이터에 해당 내용이 없습니다” 라고 응답해야 함
8. 📌 시험 대비 핵심 요약
- RAG 정의: 외부 데이터 검색 + 프롬프트 증강 → 더 정확한 답변
- Bedrock 장점: 임베딩 생성, KB 관리, FM 연결 자동화
- 벡터 DB 옵션: OpenSearch, Aurora, Neptune, S3 Vectors
- 데이터 소스: S3, Confluence, SharePoint, Salesforce, 웹페이지
- 사용 사례: 챗봇, 법률 검색, 의료 지식 Q&A
- 시험 자주 나오는 키워드
- “vector similarity search” = k-NN
- “Provisioned Throughput” = 커스텀 모델 필수
- “Fine-tuning vs RAG” → Fine-tuning = 모델 자체 수정, RAG = 데이터 추가만
✅ 추가 시험 포인트
- Fine-tuning 은 모델 가중치 변경, 비용 ↑, 데이터 필요 ↑
- RAG 는 가중치 변경 없음, 최신 데이터 반영, 비용 ↓
- Bedrock KB 는 S3, Confluence, Salesforce 등 다양한 소스와 직접 연결 가능
- Aurora (pgvector) 는 기존 SQL DB를 사용하는 기업에서 자주 언급됨

Leave a comment