📚 Amazon Bedrock — RAG & 지식 베이스 설정
이 문서는 Amazon Bedrock에서 RAG(Retrieval-Augmented Generation)
파이프라인과 지식 베이스(Knowledge Base)를 설정하는 방법을 단계별로 정리한 가이드입니다.
스토리지는 Amazon S3, 벡터 데이터베이스는 Amazon OpenSearch Serverless를 사용합니다.
1. 🔍 준비 사항
- IAM 사용자 (루트 계정 ❌, IAM 계정 ✅)
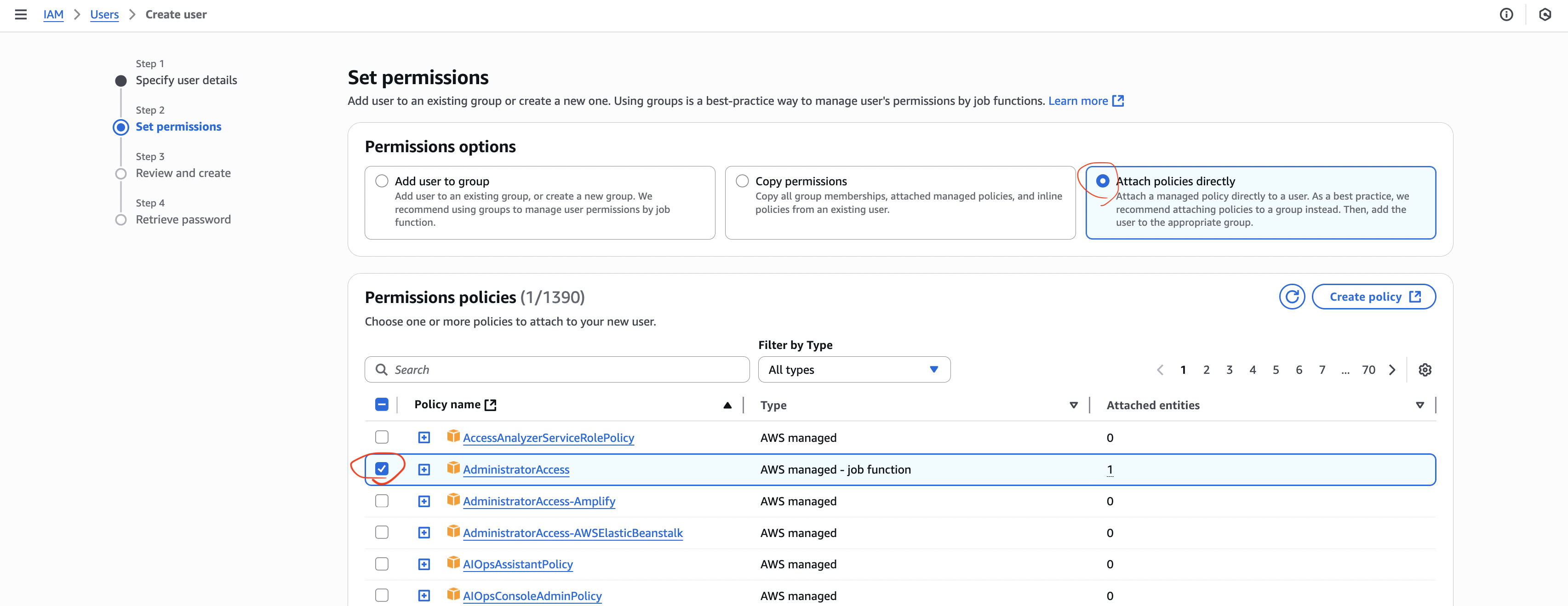
- IAM 사용자에게 AdministratorAccess 정책 부여
- 필요한 AWS 서비스:
- Amazon Bedrock
- Amazon S3
- Amazon OpenSearch Serverless (또는 외부 벡터 DB)
- 업로드할 문서 파일 (예:
evolution_of_the_internet.pdf)
2. 🛠 단계별 설정
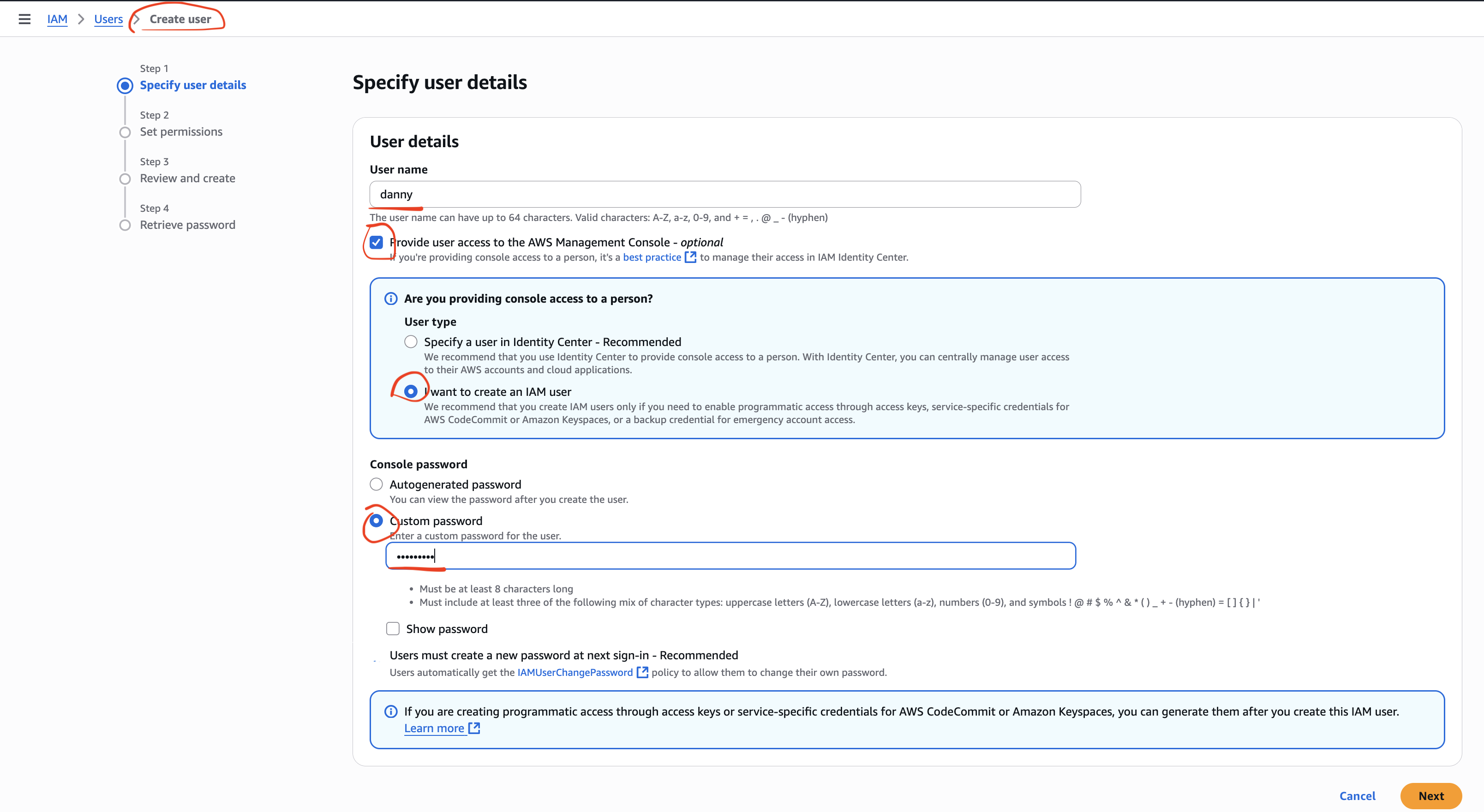
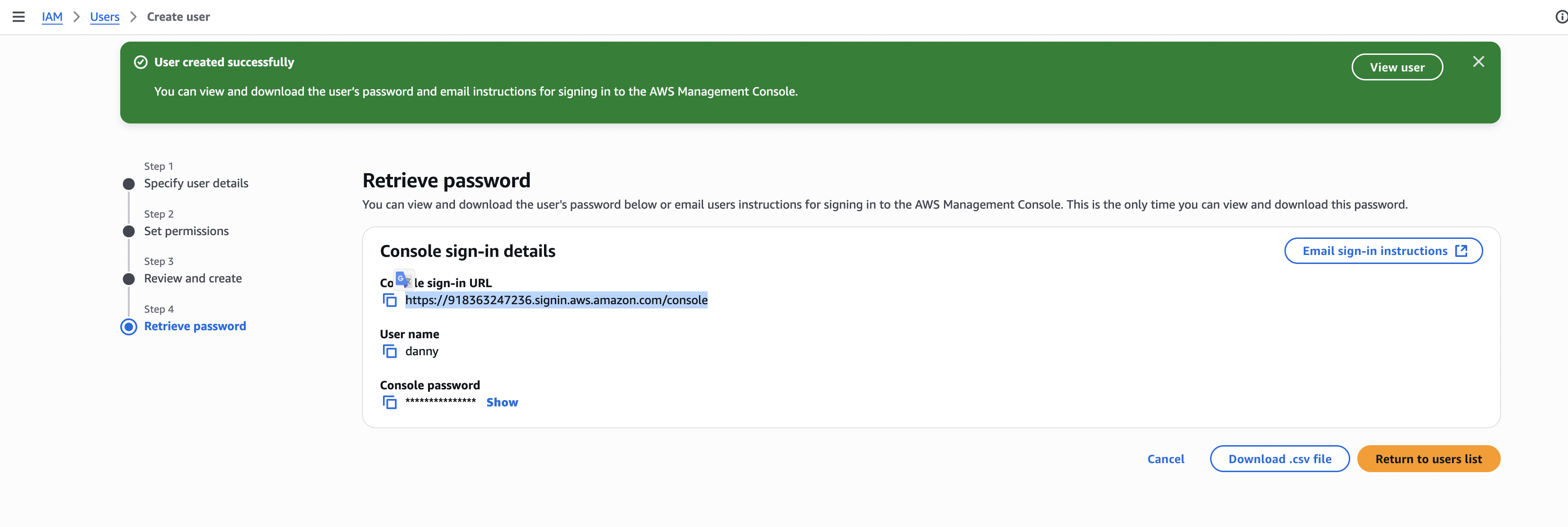
Step 1 — IAM 사용자 만들기
- IAM 콘솔 → 사용자 생성
- 사용자 이름 입력 (예:
danny) - AWS Management Console Access 활성화
- 비밀번호 설정
- AdministratorAccess 정책 연결
- 로그인 URL / 계정 정보 저장 후 IAM 사용자로 로그인
Step 2 — Bedrock에서 지식 베이스 생성
- Bedrock 콘솔 → Knowledge Bases → Create
- 지식 베이스 이름 입력
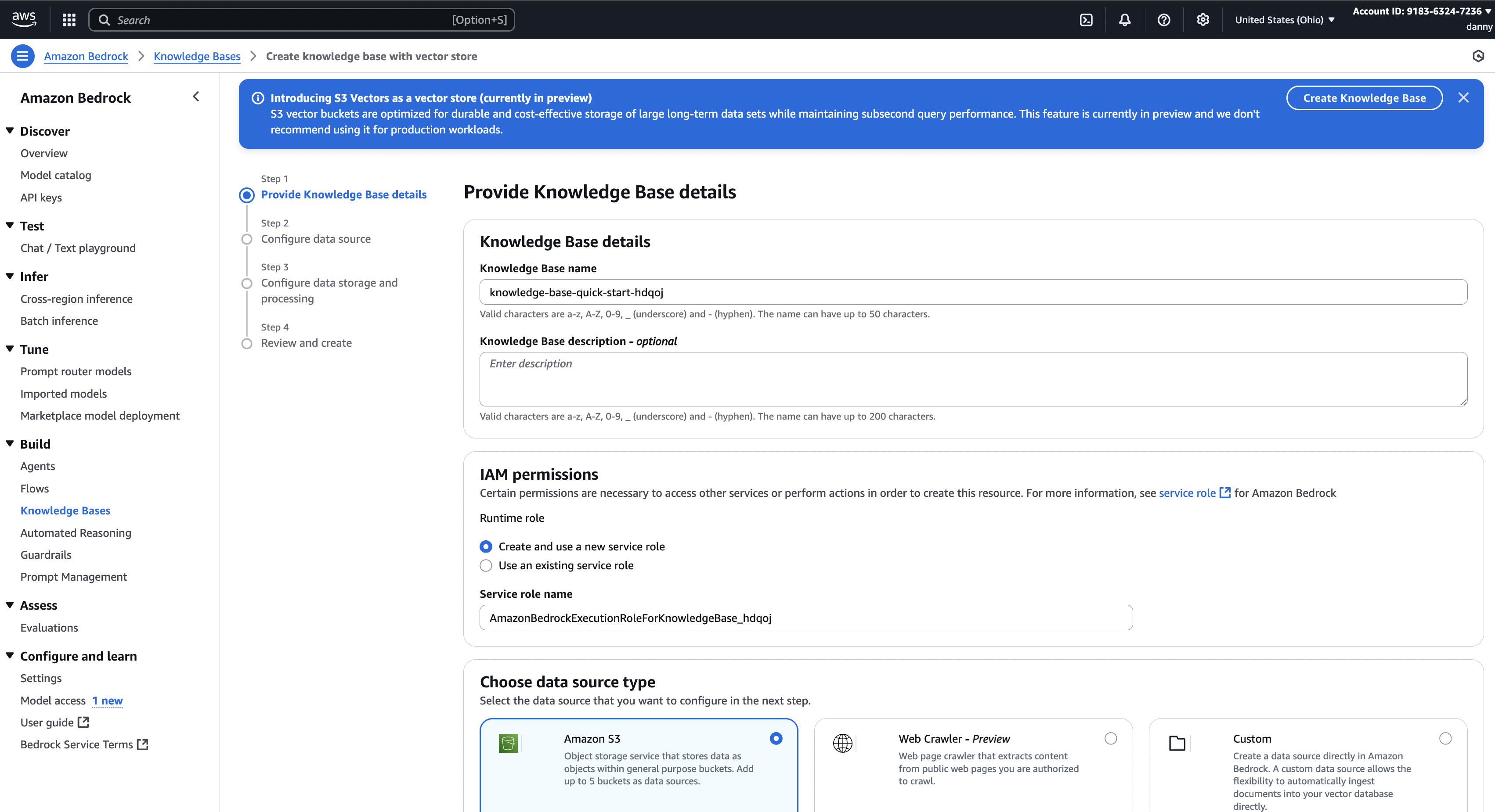
- IAM 권한 → 새 서비스 역할 생성
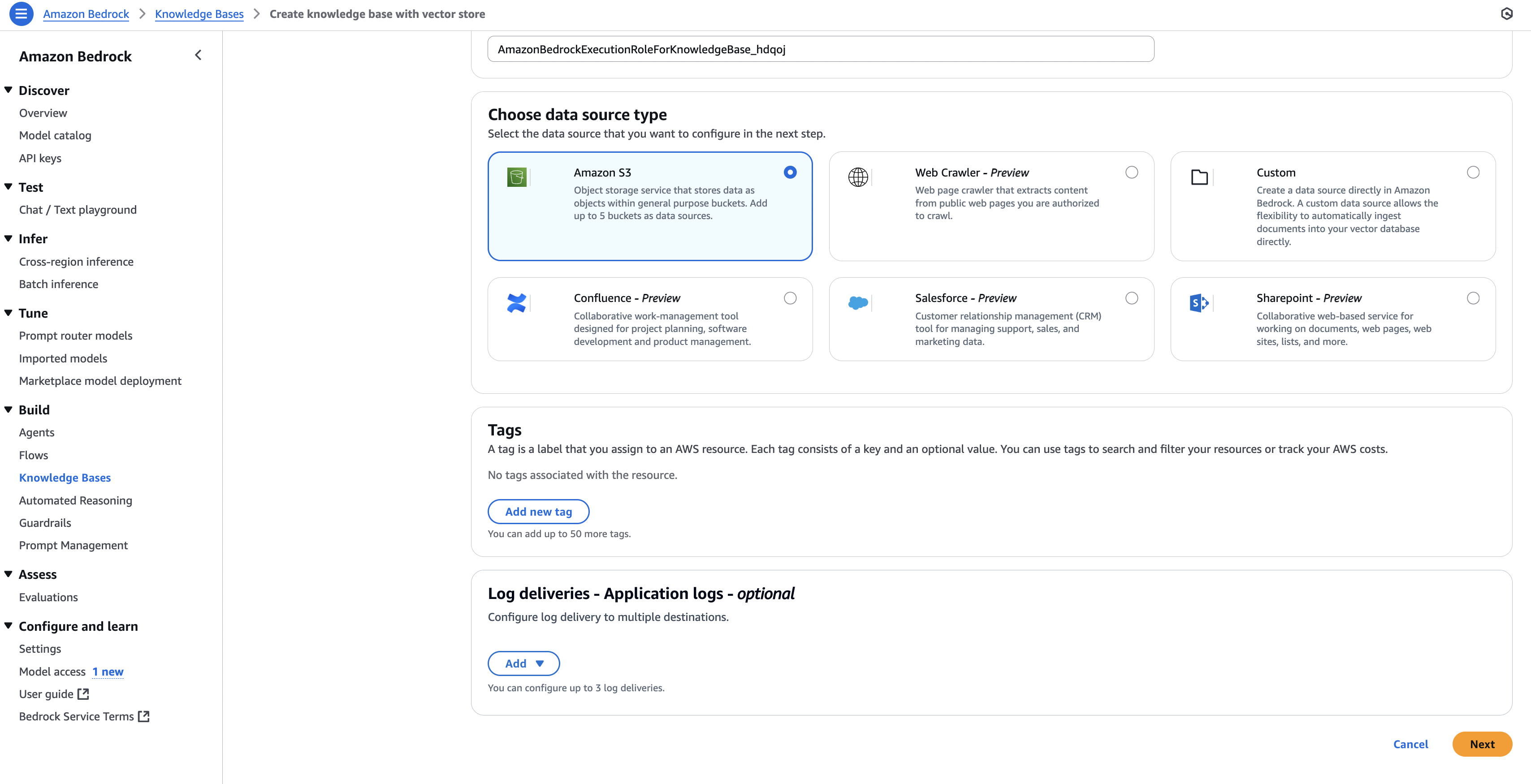
- 데이터 소스 선택 → Amazon S3
- (선택) 다른 데이터 소스:
- 웹 크롤러 (웹 페이지)
- Confluence
- Salesforce
- SharePoint
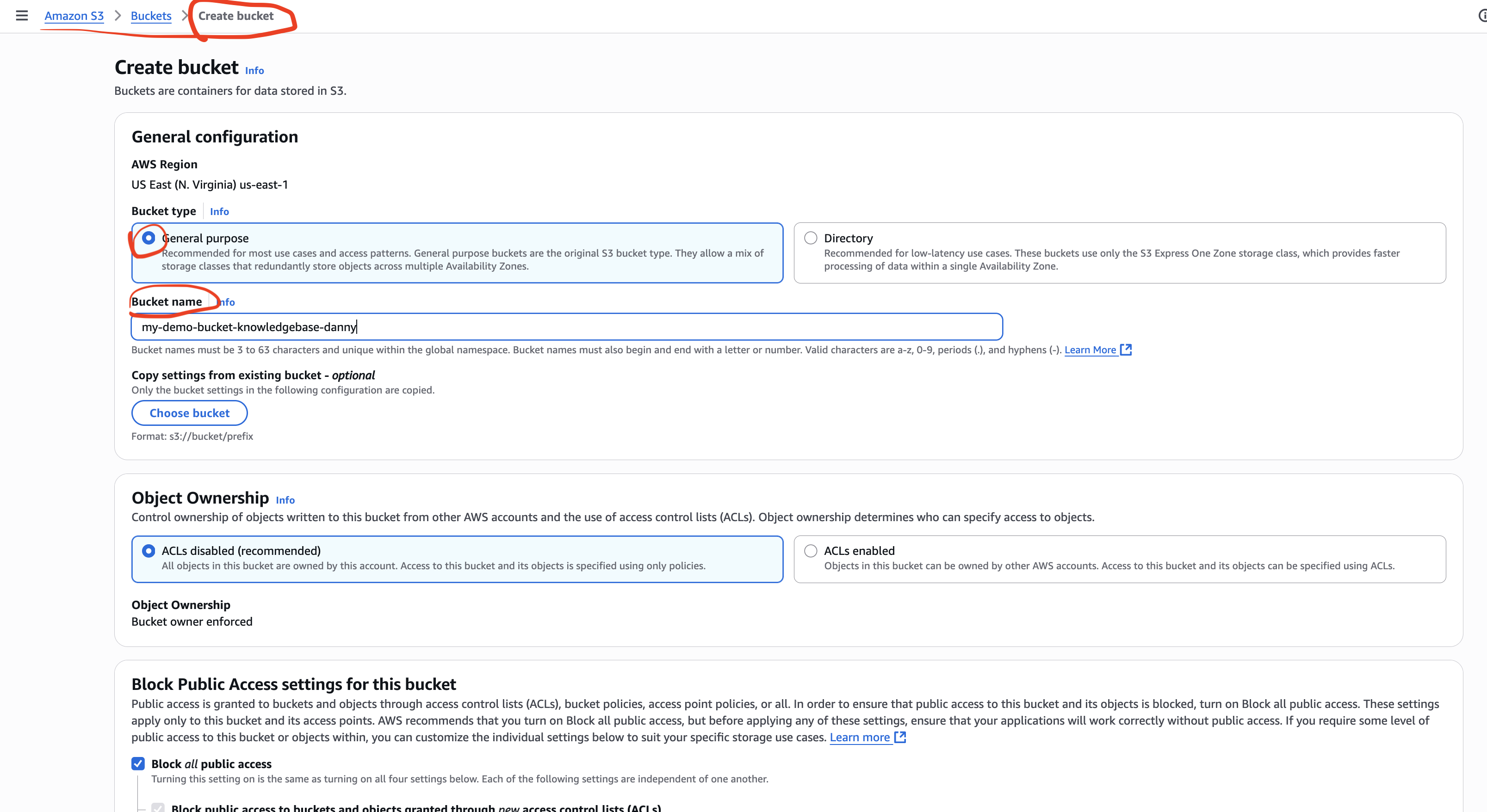
Step 3 — Amazon S3 버킷 만들고 문서 업로드
- S3 콘솔 → 버킷 생성
- 리전:
us-east-1 - 버킷 이름: 전 세계에서 유일해야 함 (예:
my-kb-bucket-danny)
- 리전:
- 문서 업로드
- 업로드 확인 (객체 리스트에서 보이는지 체크)
Step 4 — S3와 Bedrock 지식 베이스 연결
- Bedrock 지식 베이스 생성 중 → 데이터 소스에 S3 버킷 선택

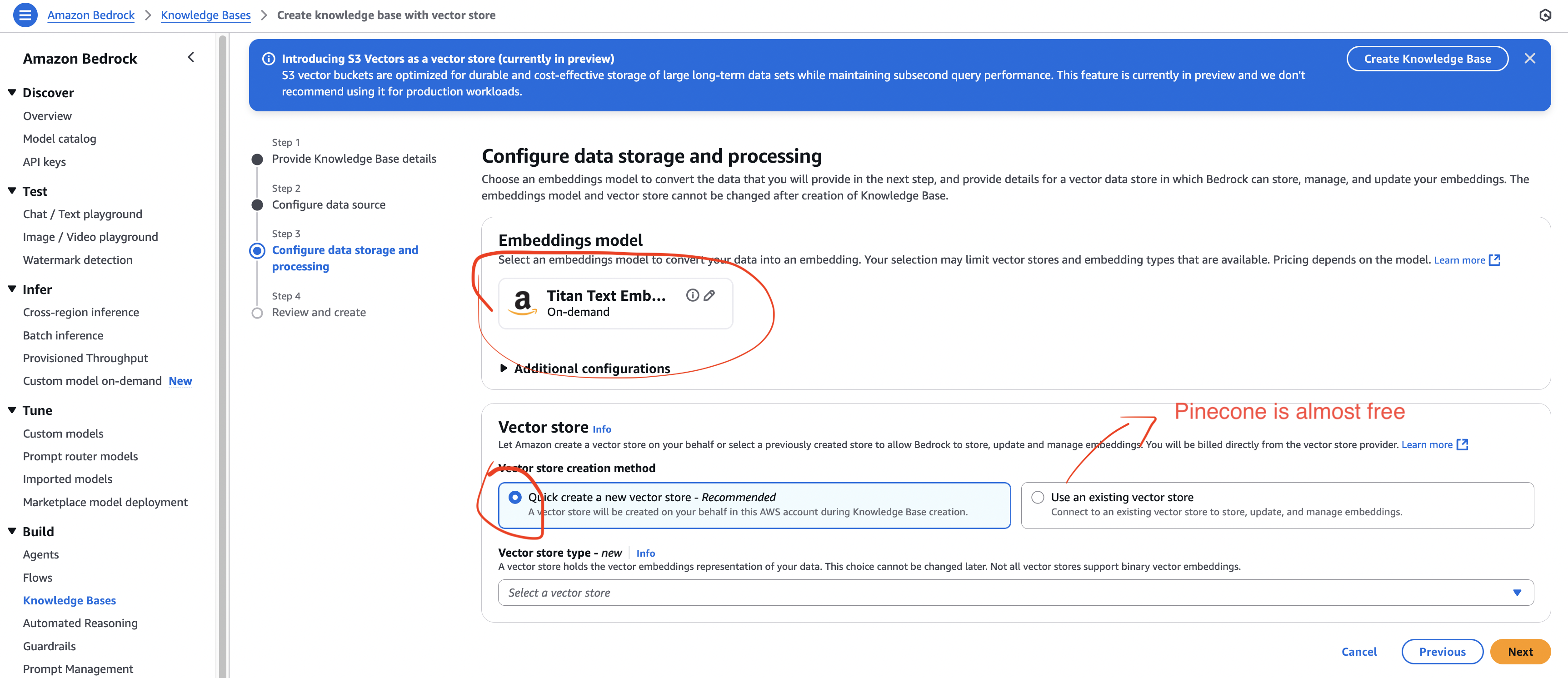
- 임베딩 모델 선택:
- Amazon Titan Text Embeddings V2 (기본)
- 벡터 데이터베이스 선택:
- 시험 대비 포인트 → Amazon OpenSearch Serverless (가장 자주 언급됨)
- 외부 DB → Pinecone(무료 티어 제공)
⚠️ 비용 주의: OpenSearch Serverless는 최소 약 \$172/월 발생 → 테스트 후 반드시 삭제 필요!
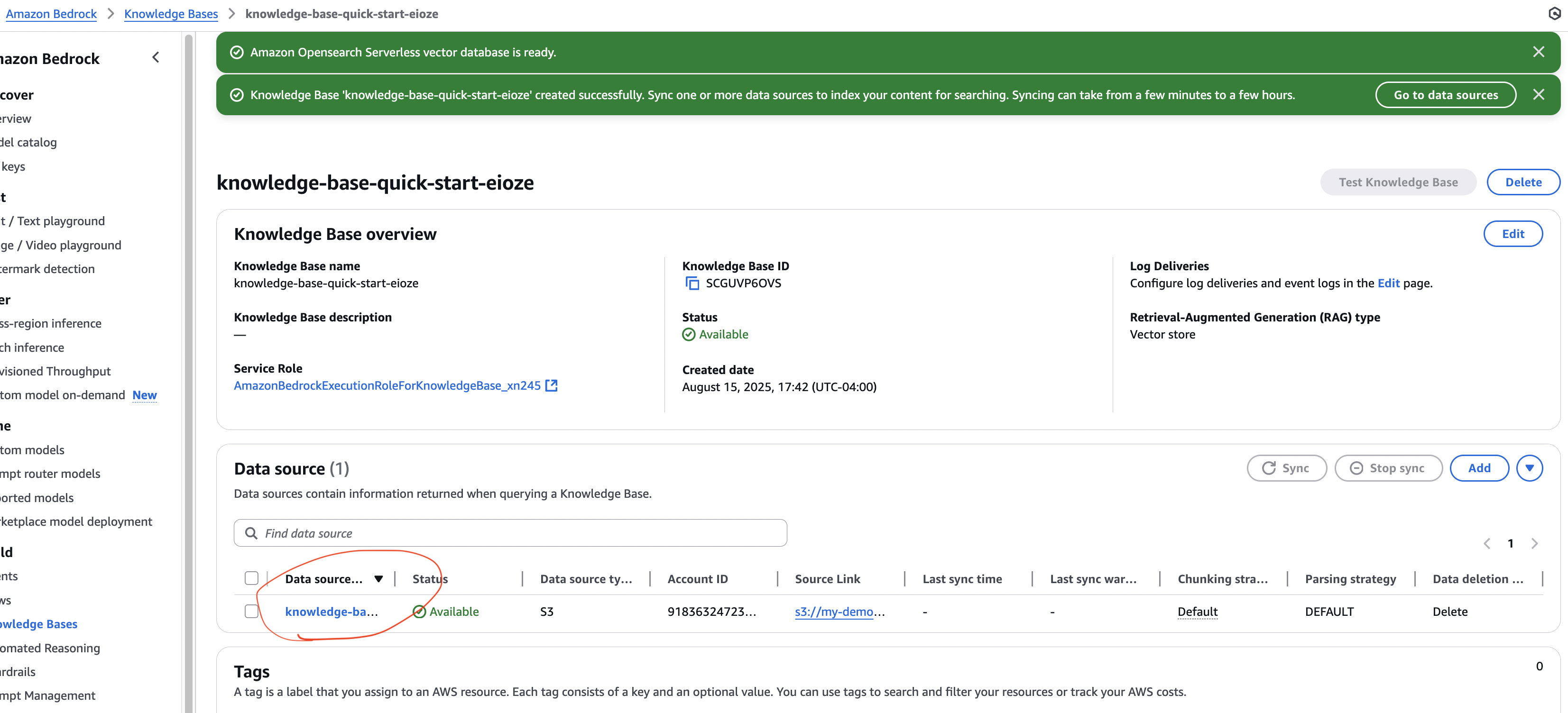
Step 5 — 데이터 동기화
- 지식 베이스에서 Sync 실행
- PDF → 텍스트 청크 분할 → 임베딩 생성 → 벡터 DB 저장
- OpenSearch에서 컬렉션 / 인덱스 확인 가능






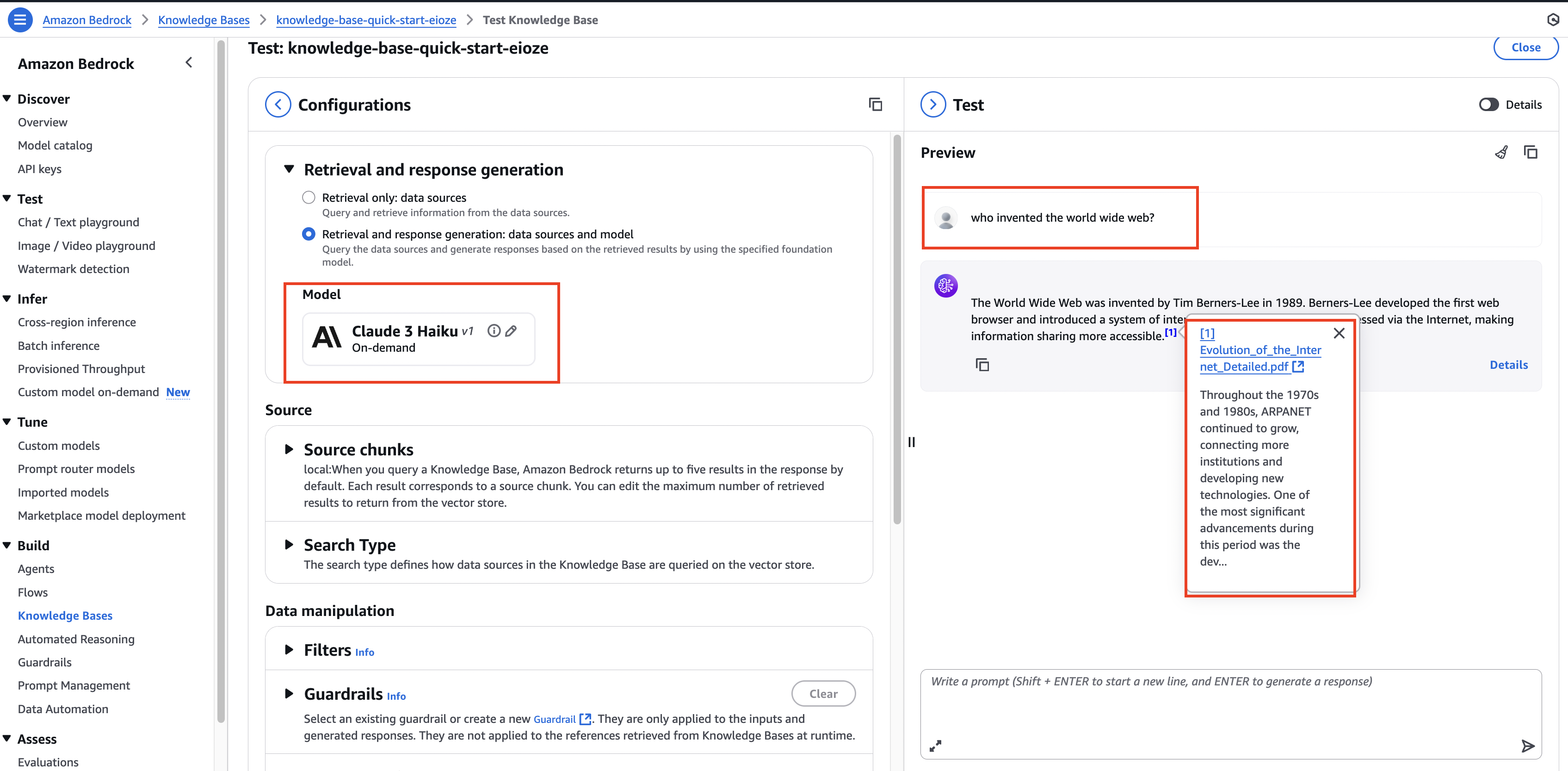
Step 6 — 지식 베이스 테스트
- 모델 선택 (예: Anthropic Claude Haiku)
- 질문 입력 (예:
"World Wide Web을 만든 사람은 누구야?") - Bedrock 내부 처리:
- 벡터 DB에서 관련 청크 검색
- 질문 + 검색 결과를 합쳐서 프롬프트 생성
- 모델이 최종 답변 생성 (출처 포함)
- 출처 링크 클릭 시 → S3 문서 열람 가능
3. 🧠 내부 동작 원리 (RAG)
flowchart TD
A[📂 Amazon S3 문서] --> B[✂️ 청크 분할 & 임베딩 생성<br/>(Amazon Titan)]
B --> C[🗄 벡터 DB<br/>OpenSearch Serverless]
C --> D[🔍 KNN 검색]
D --> E[📑 관련 청크 추출]
E --> F[📝 쿼리와 합쳐서 프롬프트 생성]
F --> G[🤖 모델이 답변 생성 + 출처 제공]
- Chunking (청크 분할): 큰 문서를 작은 단위로 나눔\
- Embeddings (임베딩): 텍스트를 숫자 벡터로 변환\
- KNN 검색: 가장 유사한 k개의 벡터를 찾아냄\
- Augmented Prompt: 원래 질문 + 검색된 내용 → 더 정확한 답변
4. 🛑 비용 절감 — 리소스 정리
테스트 끝난 후: 1. Bedrock 지식 베이스 삭제 2. OpenSearch Serverless 컬렉션 삭제 3. (선택) S3 버킷 유지 또는 삭제 (S3는 저렴)
5. 📌 시험 대비 핵심 포인트
- 루트 계정은 Bedrock 지식 베이스 생성 불가 → IAM 사용자 사용해야 함
- 벡터 DB 선택지 (시험에 자주 등장):
- OpenSearch (KNN 검색)
- Aurora PostgreSQL (pgvector 확장)
- Neptune Analytics (그래프 기반 RAG)
- S3 Vectors (저비용, 초저지연 검색)
- 외부 벡터 DB: Pinecone, Redis, MongoDB Atlas
- 데이터 소스 확장성: S3, 웹 크롤러, Salesforce, Confluence,SharePoint 등
- RAG 핵심 정의: Retrieve → Augment → Generate
✅ 정리![]()
Amazon Bedrock에서 S3 + OpenSearch 기반의 지식 베이스를 구축하고, Titan 임베딩 모델로 벡터를 생성한 뒤, KNN 검색 + LLM 응답까지 연결하는 과정을 마쳤습니다.\
이 흐름은 AWS 자격증 시험에서도 자주 등장하는 주제이므로 꼭 이해하고 기억해두세요.

Leave a comment